Zookeeper vs Chubby
上一篇博客Chubby的锁服务中已经对Chubby的设计和实现做了比较详细的实现,但由于其闭源身份,工程中接触比较多的还是它的一个非常类似的开源实现Zookeeper。Zookeeper作为后起之秀,应该对Chubby有很多的借鉴,他们有众多的相似之处,比如都可以提供分布式锁的功能;都提供类似于UNIX文件系统的数据组织方式;都提供了事件通知机制Event或Watcher;都在普通节点的基础上提供了临时节点来满足服务存活发现的功能;都以集群的方式提供服务;都通过选举产生Master并在集群间以Quorum的方式副本数据。但他们并不完全相同,并且Zookeeper还拥有后发优势,本文将重点介绍他们之间的区别,并试着分析这些区别的原因和结果。
区别根源
一个设计良好的系统应该是围绕并为其设计目标服务的,因此通过对Chubby及Zookeeper的目标比较或许能对其区别的本质略窥一二:
- Chubby:provide coarse-grained locking as well as reliable storage for a loosely-coupled distributed system.
- Zookeeper:provide a simple and high performance kernel for building more complex coordination primitives at the client.
可以看出,Chubby旗帜鲜明的表示自己是为分布式锁服务的,而Zookeeper则倾向于构造一个“Kernel”,而利用这个“Kernel”客户端可以自己实现众多更复杂的分布式协调机制。自然的,Chubby倾向于提供更精准明确的操作来免除使用者的负担,Zookeeper则需要提供更通用,更原子的原材料,留更多的空白和自由给Client。也正是因此,为了更适配到更广的场景范围,Zookeeper对性能的提出了更高的要求。
比较
围绕上述思路,接下来将从一致性、分布式锁的实现及使用、客户端Cache等方面来对比他们的不同。
一致性
- Chubby:线性一致性(Linearizability)
- Zookeeper:写操作线性(Linearizable writes) + 客户端有序(FIFO client order)
Chubby所要实现的一致性是分布式系统中所能实现的最高级别的一致性,简单的说就是每次操作时都可以看到其之前的所有成功操作按顺序完成,而Zookeeper将一致性弱化为两个保证,其中写操作线性(Linearizable writes)指的是所有修改集群状态的操作按顺序完成,客户端有序(FIFO client order)指对任意一个client来说,他所有的读写操作都是按顺序完成。从实现上来看:
- Chubby的所有读写请求都需要交给Leader串行执行,并且Leader会用一致性协议复制到集群所有节点。
- Zookeeper仅将写操作交给Leader串行执行,也就保证了写操作线性。对于读操作,则由与客户端连接的Server自行处理,客户端有序的保证也很简单,Zookeeper给每个写入后的状态一个唯一自增的Zxid,并通过写请求的答复告知客户端,客户端之后的读请求都会携带这个Zxid,直连的Server通过比较Zxid判断自己是否滞后,如果是则让读操作等待。
对比Chubby及Zookeeper的一致性保证可以看出,Zookeeper损失的是不同客户端的读写操作的一致性,如下图所示:
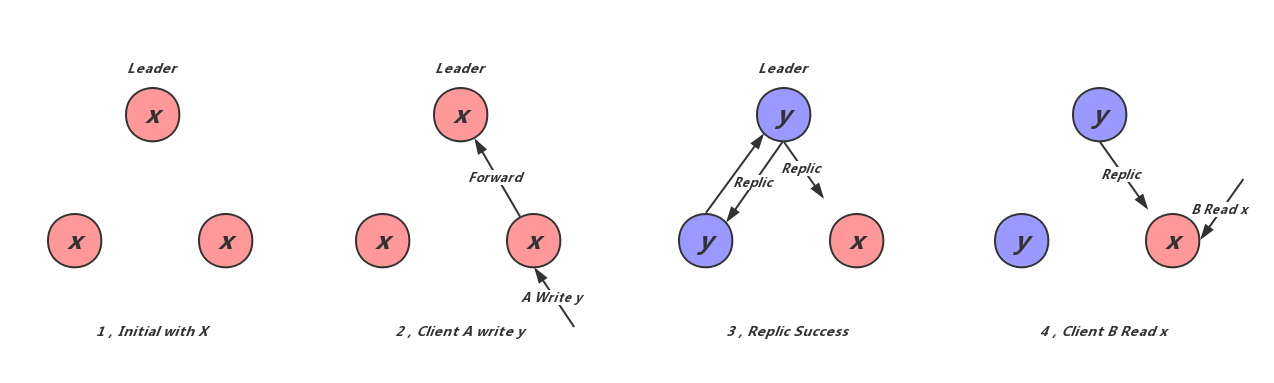
Zookeeper集群的初始状态为x;Client A发起写操作将状态修改为y,写操作由于写操作线性的保证转发给Leader通过一致性协议复制到整个集群,过半数节点成功后返回成功;此时ClientB读还未同步到的Server,获得x。这种一致性的损失,换来的是集群读请求的高性能。对于不能容忍这种不一致的场景,Zookeeper提供两种机制满足:
- Watcher通知跟Read操作一样是由客户端锁连接Server本地处理的,所以Client B收到对应的事件通知后再Read就一定能看到最新的状态y;
- 由于客户端有序的保证,Client B可以在Read操作前加一条Write操作,来保证看到最新状态,为了避免这个不必要的Write操作Zookeeper提供Sync命令,相当于一条空的写操作。
这也符合Zookeeper的设计思路:提供更高效更原子的操作,通过这些操作客户端可以自行组装满足各种需求,即便是对一致性要求更高的需求。
分布式锁
上一篇博客Chubby和锁服务中已经分析了Chubby的分布式锁的设计实现,分布式锁从实现到使用认为可以分为一致性协议,锁的实现和锁的使用三个部分,相对于Chubby,Zookeeper倾向于实现更少的部分,而将更多的选择交给用户:
- Chubby:提供准确语义的Lock,Release操作,内部完成了一致性协议,锁的实现的内容,仅将锁的使用部分留给用户;
- Zookeeper:并没有提供加锁放锁操作,用户需要利用Zookeeper提供的基础操作,完成锁的实现和锁的使用部分的内容,如下图所示:
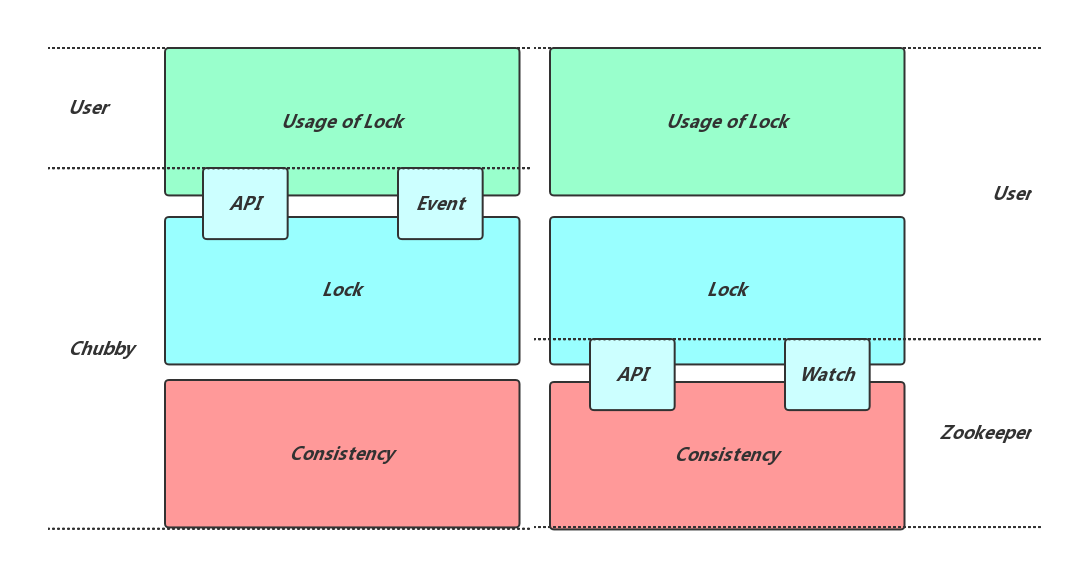
因为如此,用户在使用Zookeeper来获得锁功能的时候会稍显复杂,以读写所为例,Chubby可以通过接口直接使用,而Zookeeper需要的操作如下:
Write Lock
1 n = create(l + “/write-”, EPHEMERAL|SEQUENTIAL)
2 C = getChildren(l, false)
3 if n is lowest znode in C, exit
4 p = znode in C ordered just before n
5 if exists(p, true) wait for event
6 goto 2
Read Lock
1 n = create(l + “/read-”, EPHEMERAL|SEQUENTIAL)
2 C = getChildren(l, false)
3 if no write znodes lower than n in C, exit
4 p = write znode in C ordered just before n
5 if exists(p, true) wait for event
6 goto 3
用户需要在某个ZNode下创建代表自己的临时子节点来抢写锁,同时这个子节点有一个自增的编号,编号最小的节点获得写锁,其他节点关注其前一个ZNode的存在,如果消失会收到watcher通知,之后继续尝试加写锁;读锁稍宽松,只要没有比自己编号更小的写节点就可以加读锁成功。
客户端Cache
- Chubby:内部维护,一致性cache;
- Zookeeper:Client自己实现,通过watcher控制;
Chubby和锁服务介绍过,Chubby通过Server和客户端Lib的配合在内部维护了完整的客户端缓存功能,并且这个客户端缓存是一致性的,这就极大的简化了用户的使用成本,因为用户根本不需要知道Cache的存在。相对应,Zookeeper根本没有实现Cache功能,用户如果需要必须自己实现,利用watcher机制,用户能方便的按自己需求实现一致或不一致的Cache语义。
API
比较Chubby和Zookeeper的API设计可以看出Zookeeper围绕自己设计目标的接口设计:
- Zookeeper取消Handle,因此省略了Open,Close接口,这就要求所有对ZNode的访问都需要提供完整的Path。这样是很合理的,因为Zookeeper定位提供基础接口,那么上层使用时很有可能是需要很多个ZNode配合完成的,从上面介绍的锁的实现便可以看出,这样一来维护多个Handle反而造成了使用负担;
- Zookeeper没有提供Lock,Release等精确语义的锁操作;
- Zookeeper提供Sync操作来满足对更高的一致性要求的场景。
总结
通过上面的分析可以看出Chubby和Zookeeper设计定位的区别,以及为了各自目标作出的设计实现的努力。Chubby追求使用简单,Zookeeper追求使用自由,简单就一定有更多的限制,自由就一定更多的使用成本,究竟孰好孰坏,就是个见仁见智的问题了。其实类似的权衡在计算机科学中是非常常见,比如库或框架的设计,比如高级语言的语法设计。
参考
The Chubby lock service for loosely-coupled distributed systems
ZooKeeper: Wait-free coordination for Internet-scale systems