Zeppelin不是飞艇之存储节点
通过上一篇Zeppelin不是飞艇之概述的介绍,相信读者已经对Zeppelin有了大致的了解,这篇就将详细介绍其中的存储节点集群(Node Server)。存储节点负责最终的数据存储,每个Node Server会负责多个分片副本,每个分片副本对应一个DB和一个Binlog。同一分片的不同副本之间会建立主从关系,进行数据同步,并在主节点异常时自动切换。本文将从请求处理、线程模型、元信息变化、副本同步及故障检测来展开介绍,最后总结在存储节点的设计开发过程中的两点启发。
请求处理
Node Server会与Client直接连接,接受用户请求,处理过程会经过如下层级:
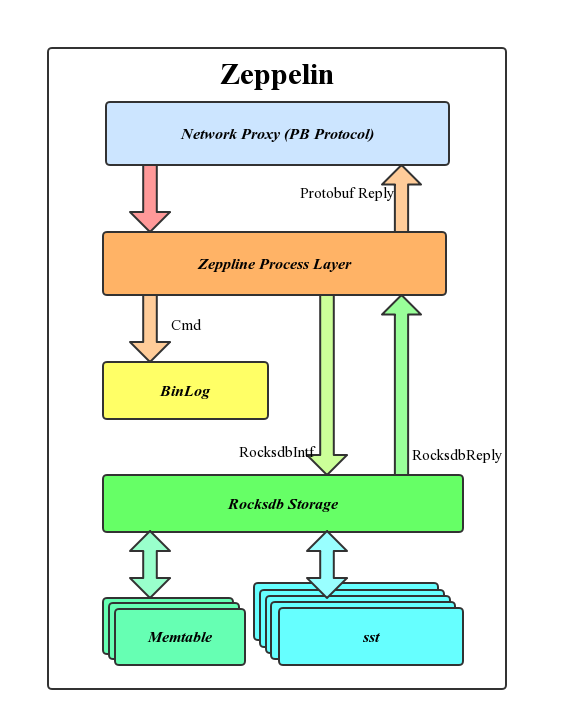
Client与存储节点Node之间用Protobuf协议通信,网络模块会先进行协议解析;之后进入命令的处理层,区分命令类型,判断合法性及读写属性;写请求会先写Rocksdb,之后写Binlog,Binlog被用来进行副本主从间的数据同步;Rocksdb是LSM(The Log-Structured Merge-Tree)的优秀实现,数据会先被写入Rocksdb的内存Memtable及Log,并在之后的Compaction中逐步写入不同层级的SST文件中去。
线程模型
Zeppelin的线程模型如下图所示:
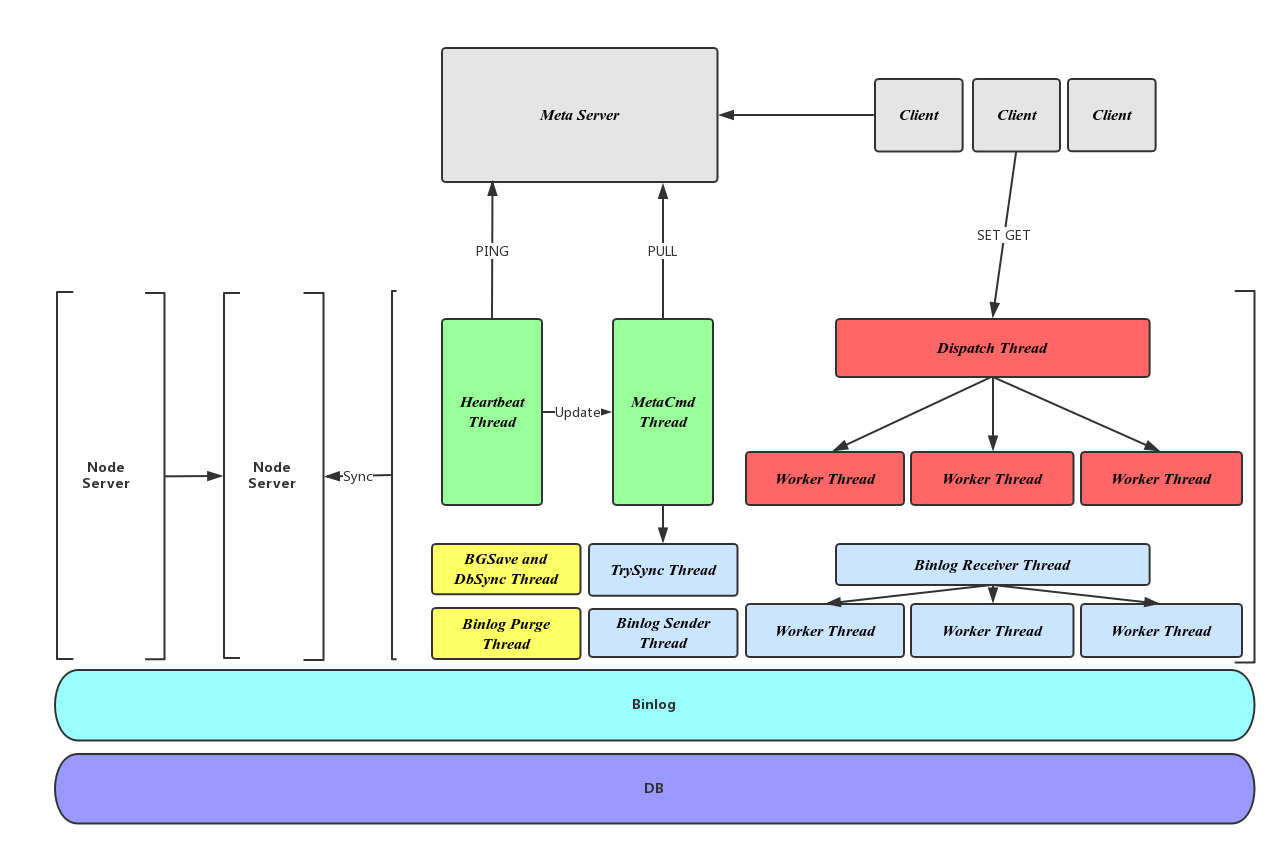
通过不同的颜色我们将Zeppelin的线程分为四大块:
- 用户命令处理模块:包括红色显示的Dispatch Thread和Worker Thread,Dispatch线程接受请求,建立连接,并将连接分发给不同的Worker线程;Worker线程与Client通信,接受请求、处理命令、返回结果。
- 副本同步模块:如图中蓝色所示,TrySync线程为所有本节点负责的Slave分片向Master发起数据同步请求;Binlog Sender线程负责Binlog的发送;Binlog Receiver,Receiver Worker负责Binlog的接受和处理,与用户命令处理模块类似。
- 元信息模块:绿色所示,包括与Meta进行心跳的Heartbeat线程及拉取元信息并更新本地状态的MetaCmd线程。
- 后台辅助模块:Binlog Purge线程定时删除过期的Binlog以维持较小的空间占用,BgSave and DbSync线程负责分片的备份及与Slave分片的全量数据发送。
元信息变化
当有节点起宕,节点加入退出或创建删除表等元信息变化时,存储节点需要感知并作出对应的改变。正常情况下,存储节点Node与元信息节点Meta之间维持一个心跳,Meta通过心跳向Node发送当前的元信息版本号Epoch,Node向Meta发送当前负责分片的Binlog偏移量。元信息改变时,Node会从心跳得到更大的Epoch,这时Heartbeat线程通知MetaCmd线程向Meta主动发起Pull请求,获得最新的元信息,之后Node进行对应的主从迁移,分片添加删除等操作。
副本同步
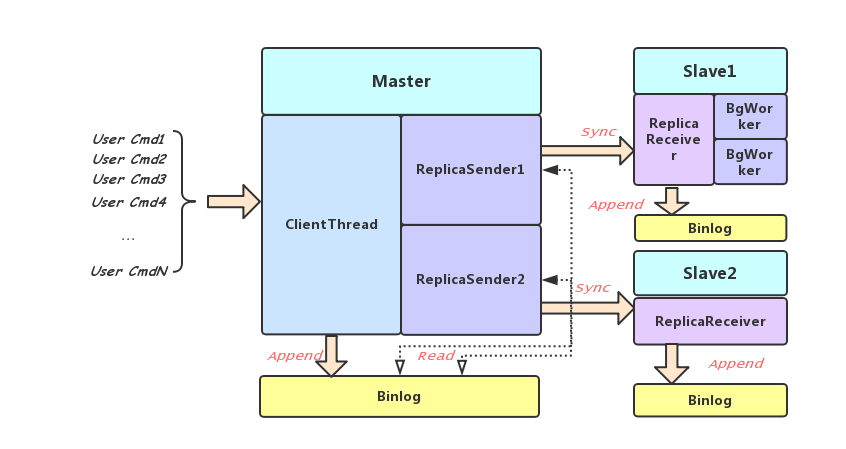
Zeppelin的副本之间采用异步复制的方式,由Slave发起建立主从关系,当存储节点发现自己所负责的分片有主从关系变化时,会触发Slave向对应的Master发起TrySync请求,TrySync中携带Slave当前的Binlog偏移,Master从该偏移顺序发送Binlog信息。下图所示是主从之间配合数据同步的线程关系。
Binlog
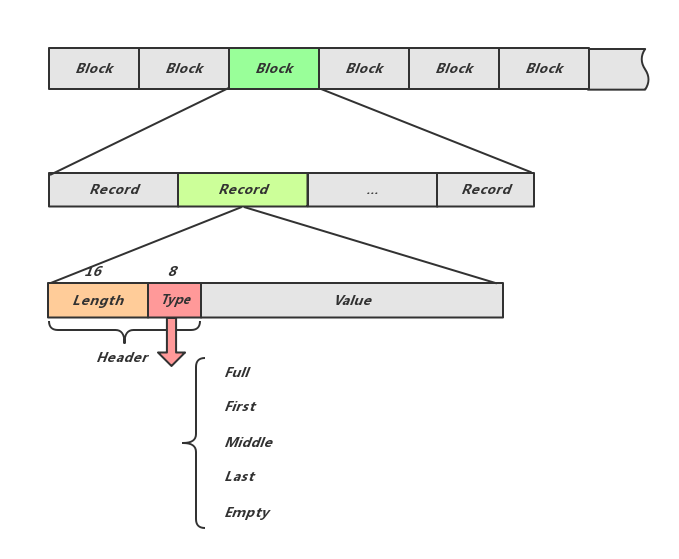
Binlog支持尾部的Append操作,由多个固定大小的文件组成,文件编号和文件内偏移一起标记一个Binlog位置。如下图所示,每条用户的写请求被记录在一个Record中,Record Header记录了Value的Length,校验Checksum及类型Type,Type Full表示Record被完整的记录在一个Block中,First,Middle,Last表示该Record横跨多个Block,当前是开头,中间或是结尾的部分。
可以看出每个Record的解析,十分依赖从Header中读到的Length,那么当Binlog文件中有一小段损坏时,就会因为无法找到后一条而损失整个Binlog文件,为了降低这个损失,Binlog被划分为固定大小的Block,每个Block的开头都保证是一个Record开头,Binlog损坏时,只需要略过当前Block,继续后续的解析。
Binlog发送
当主从关系建立以后,Master副本需要不断的给Slave副本发送Binlog信息。我们之前提到,一个分片都会对应一个Binlog,当有很多分片时,就没有办法给每个Binlog分配一个发送线程。因此Zeppelin采用了如下图所示机制:当前存储节点所负责的每个Master分片的Binlog发送任务被封装为一个Task,Task中记录其对应的Table,分片号,目标Slave节点地址,当前要发送的Binlog位置(文件号加文件内偏移)。所有的Task被排成一个FIFO队列,固定个数的Binglog发送线程从队列头中取出一个Task,服务固定的时间片长度后将其插回队列尾部。
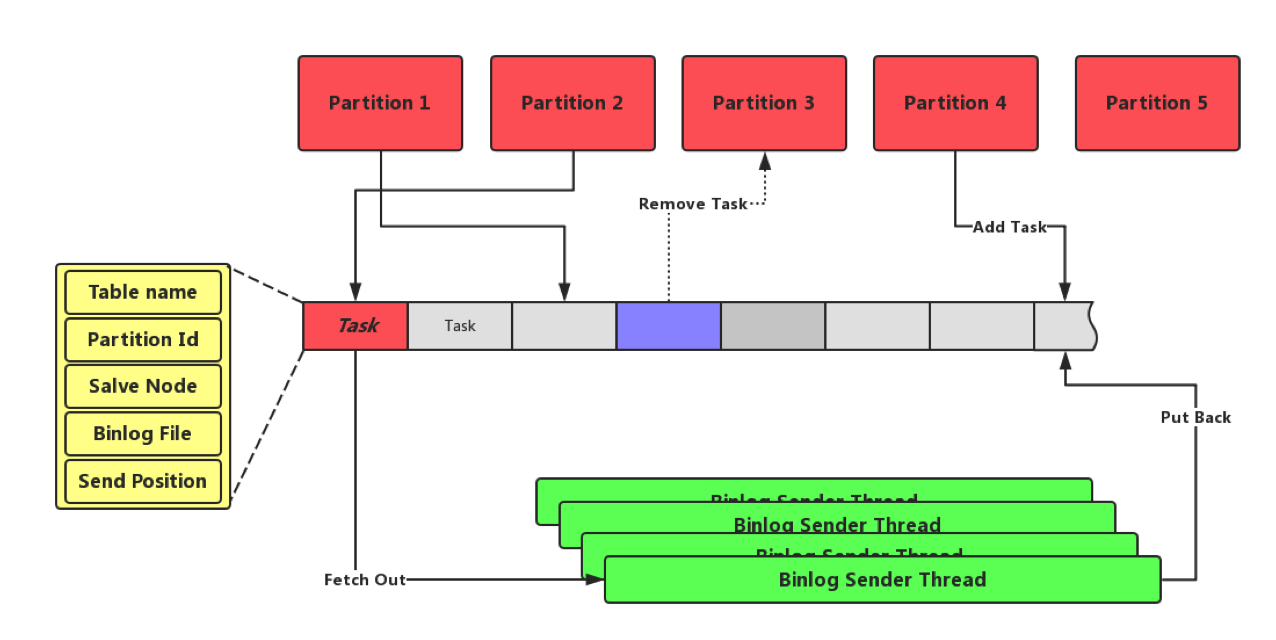
针对每个Task,Binlog发送线程会从当前的Binlog偏移量发送顺序发送Binlog Record的内容给对应的Slave的接受线程,并更新Binlog偏移。
Binlog接收
对应节点的Binlog Receive线程会接受所有来自不同Master分片的Binlog消息,按照分片号分发给多个Binlog Worker,Binlog Worker顺序执行Binlog消息,同样要写DB及Binlog,从而完成与Master分片的数据同步。
Binlog压缩及全同步
可以看出Binlog同样需要占用大量的磁盘空间,为了不使这种消耗无限增长,Zeppelin设置保留Binlog的时间和个数,并定时清理不需要的Binlog文件,称为Binlog压缩。
这带来了新的问题,当Master收到Trysync请求时,发现Slave的Binlog 偏移量指向的Binlog文件已经被删除,正常的部分同步无法建立。这时就需要全同步的过程,Master分片会先将当前的DB打一个快照,并将这个快照及快照对应的Binlog位置发送给Slave,Slave替换自己的DB,并用新的Binlog位置发起新的Trysync过程。
Zeppelin利用LSM引擎所有文件写入后只会删除不会修改的特性,通过硬链实现秒级的快照,同时快照本身也不会占用过多空间。相关内容可以参考Rocksdb Checkpoint。
Binlog一致
需要注意的是分片副本间主从关系并不稳定,会由于节点的起宕或网络的中断自动切换,为了保证新的主从关系可以正常建立,我们要求每个Binlog Record的位置在所有的副本看来是一致的,也就是副本间的Binlog一致。Zeppelin采取了如下策略:
- Binlog检查拒绝机制:Slave副本检查Binlog的发送方地址、发送方元信息版本及前一条Binlog的偏移,拒绝错误的Binlog请求。这些信息也需要在Master副本所发送的Binlog请求中携带。
- Trysync偏移回退机制:当Master副本收到Trysync的偏移大于自己或者不合法时,需要通知对方回退到一个指定的合法的位置,以完成主从关系的正常建立。这种情况会发生在频繁的副本主从切换。
- Master触发Skip机制:Master副本发现Binlog损坏时,会略过一个或多个Block,为了保证Binlog一致,此时Master需要强制要求所有的Slave略过同样长度的Binlog。通过特殊的Skip命令来完成这个任务。Slave的Binlog会填充同样长度的一段类型为Empty的空白内容。
故障检测
节点异常
节点异常时,元信息节点会感知并完成需要的主从切换,并通知所有的存储节点,发生变化的节点会进行状态迁移并建立新的主从关系。
主从链接异常检测及恢复
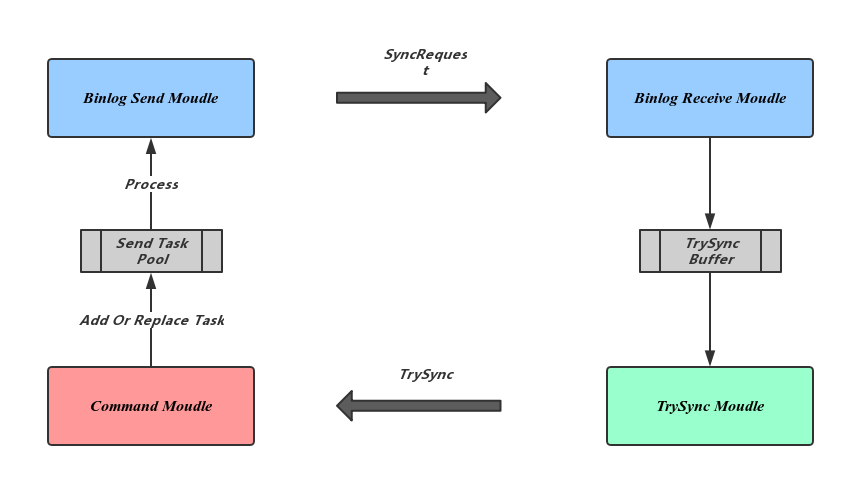
为了副本复制的高效,Binlog的发送采用单向传输,避免了等待Slave的确认信息,但这样就无法检测到主从之间链接的异常。Zeppelin复用了BInlog发送链路来进行异常检测,如下图所示,左边为Master节点,右边为Slave节点:
-
Slave副本维护一个Master的超时时间和上一次通信时间,收到合法的Binlog请求或Lease命令会更新通信时间。否则,超时后触发TrySync Moudle发起新的主动同步请求。Master在收到新的TrySync请求后会用新的Binlog发送任务替换之前的,从而恢复Binlog同步过程。
-
Master动态更新Slave超时时间:由于我们用固定数量的Binlog Sender负责所有分片的Binlog发送,上面提到,当某个发送任务的时间片用完后会被放回到任务队列等待下一次处理,当Master负载较高时这个间隙就会变长。为了不让Slave无效的触发TrySync,每次时间片用完被放回任务队列前,Master都会向Slave发送Lease命令,向Slave刷新自己的超时时间。这个超时是通过Master节点的当前负载动态计算的:
Timeout = MIN((TaskCount * TimeSlice / SenderCount + RedundantTime), MinTime)
Lessons We Learn
1,限制资源线性增长
分片个数是Zeppelin的一个很重要的参数,为了支持更大的集群规模,需要更多的分片数。而因为分片是数据存储,同步,备份的最小单位,分片数的增多势必会导致资源的膨胀,Zeppelin中做了很多设计来阻止这种资源随分片数的线性增长:
- 减少Binlog发送线程数:通过上面介绍Task Pool及Slave的动态租约来限制Binlog发送线程数;
- 限制Rocksdb实例增多带来的资源压力:通过多实例公用Option来实现共享Flush,Compact线程,内存配额等;
- 减少心跳信息:通过DIFF的方式来减少Node与Meta之间交互的分片Binlog Offset信息。
2,异步比同步带来更多的成本
无论是副本同步还是请求处理,异步方式都会比同步方式带来更好的性能或吞吐。而通过上面副本同步部分的介绍可以看出,由于采用了异步的副本同步方式,需要增加额外的机制来保证Binlog一致,检测链路异常,这些都是在同步场景下不需要的。给了我们一个启发就是应该更慎重的考虑异步选项。
之后在Zeppelin不是飞艇之元信息节点中,将详细介绍Zeppelin的另一个重要角色Meta。