如何验证线性一致性
线性一致性(Linearizability)是分布式系统中常见的一致性保证。那么如何验证系统是否正确地提供了线性一致性服务呢?本文希望从‘什么是线性一致性’,‘如何验证线性一致性’,问题复杂度,常见的通用算法,以及工程实现五个部分,直观、易懂地回答这个问题。
什么是线性一致性
MAURICE P. HERLIHY 和 JEANNETTE M. WING曾在“ Linearizability: A Correctness Condition for Concurrent Objects ” 中对线性一致性给出了形式化的定义和证明,对分布式系统来说,简单的讲就是即使发生网络分区或机器节点异常,整个集群依然能够像单点一样提供一致的服务,即依次原子地执行每一条操作。假如我们可以站在最终操作执行的视角,将整个系统看做一个整体,一个保证线性一致性的服务应该如下图所示进行服务:
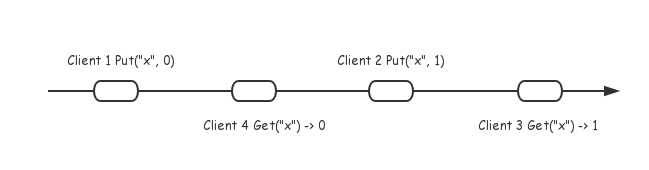
由于每条操作是依次、原子的执行,相互之间没有重叠,为了方便理解,可以把一个操作在图上简化为一个点。如下图所示:
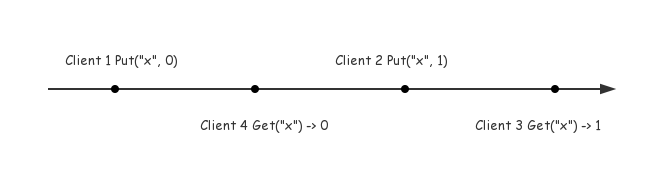
然而,实际情况中,分布式系统通常是很多节点作为一个整体对外提供服务,并在内部处理网络或节点异常,我们无法站在上帝视角看到其执行序列。同时,我们真正关心的也是其作为一个整体对外的表现,而不是其中的每个单独节点。我们所能做的是站在客户端的角度,通过读写事件的发起和结束来感知整个系统。正如站在地球上仰望星空,通过光来感知天体,看到的每一次闪烁,可能真正发生在上万年之前。因此,下图才是真正可以看到的情况:
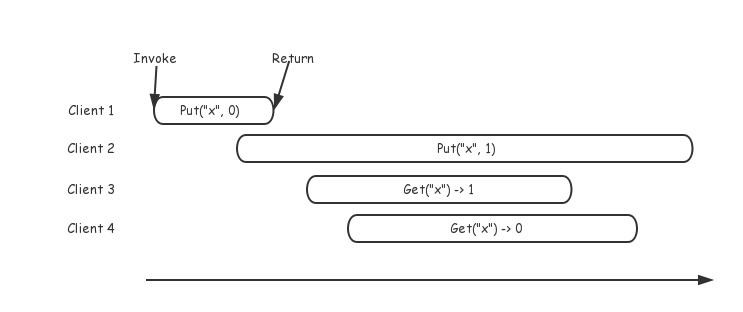
上图,展示了在每个客户端看来,其请求从发起到结束的时间点。因此,我们希望通过一系列客户端的执行和返回序列来判断系统是否正确提供了线性一致性服务。
如何验证线性一致性
为了判断系统是否正确提供了线性一致性,首先在运行过程中获得一系列不同的执行历史,接着验证每组历史是否满足线性一致性,只要有一个不满足,便可以说系统不满足线性一致性。但如果没有发现不满足的历史,也不证明系统一定正确。然而,在工程中通过对大量的执行历史的验证,使得我们对自己的系统更充满信心,这就足够了。那么现在的问题转变为:如何验证一组执行历史是否满足线性一致性。
通过客户端可以看到一个读写请求的发起和结束时间,而其真正在服务端的执行可能发生在开始和结束中间的任意一点。因此,验证线性一致性的关键就是找到一组依次执行的序列,如果这组执行序列存在,则可以说这组执行历史是满足线性一致的,如下图所示:
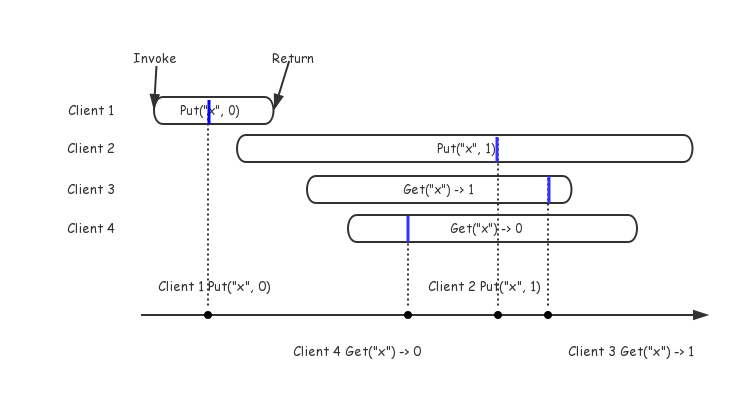
明显的,存在这么一组序列,因此我们说这组执行历史是符合线性一致性的。再来看一个不符合线性一致性的例子,如下图,可以看出,由于Client 3已经读到1,说明在Client 3请求结束前Client 2已经写成功,而又没有其他请求再次修改x的值,因此Client 4不应该在之后读到0。
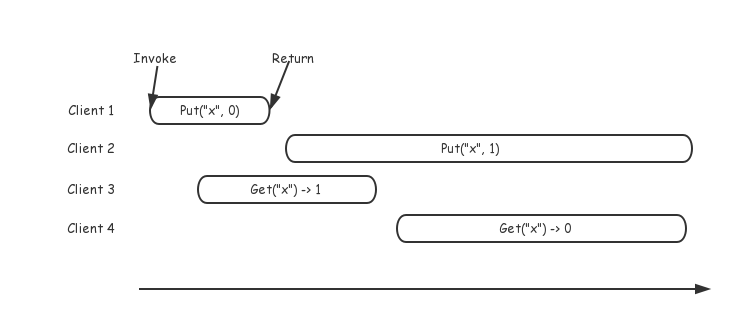
实践中,通常会通过在频繁注入异常的情况下,随机生成请求序列,收集执行的发起和结束历史,并寻找合理的线性执行序列,如Jespen。
问题复杂度
直观来看,这个问题是一个排列问题,极端情况下的时间复杂度为O(N!)。事实上,Phillip B. Gibbons和Ephraim Korach在Testing Shared Memories中已经证明其是一个NP-Complete问题。虽然Gavin Lowe在Testing for Linearizability中给出了一些特殊限制下的多项式甚至是线性复杂度的算法,但在通用场景下,判定线性一致性并不是一个容易解决的问题,其搜索空间会随着执行历史的规模急速膨胀。
通用算法
虽然判定线性一致性的复杂度极高,但我们还是能够通过一些技巧,在大多数场景下,在工程可接受的时间内给出结果,这里介绍三个常见的,且一脉相承的通用算法。在此之前,先对算法面临的问题进行抽象,以下图执行历史为例,给出算法的输入和期待的输出:
Input: 调用历史
1,Client1: Invoke Put x=0
2,Client2: Invoke Put x=1
3,Client1: Return Put x=0
4,Client3: Invoke Get x
5,CLient4: Invoke Get x
6,Client3: Return Get 1
7,Client4: Return Get 0
8,Client2: Return Put x=1
Output: 执行序列
Client1 Put x=0
Client4 Get 0
Client2 Put x=1
Client3 Get 1
1,WG算法
请求的调用历史中,存在着一种偏序关系:Prev,如果一个请求的Return发生时间早于另一请求的Invoke,我们便称其Prev另一个请求。显而易见,这种偏序关系是一致性验证算法必须要保留的。祸兮福所倚,也正是这种对偏序关系的保留,给了算法加速的可能。WG算法的思路非常简单:从调用历史中找出没有Prev的项,将其对应的请求执行并取出,之后对剩下的调用历史重复该算法,直到没有更多的调用历史或执行结果不满足。
如上述例子中,“Client1 Put x=0” 和 “Client2 Put x=1” 由于其Invoke前没有任何请求Return,可以首先被取出。假如选择“Client1 Put x=0”,将其对应的Invoke和Return从调用历史中取出,得到新的历史:
2,Client2: Invoke Put x=1
4,Client3: Invoke Get x
5,CLient4: Invoke Get x
6,Client3: Return Get 1
7,Client4: Return Get 0
8,Client2: Return Put x=1
和一条已经序列化的请求:
Client1 Put x=0
此时可以看到剩余的历史中,每一个请求的Invoke前都没有其他请求的Return,因此都可以作为下一个取出的选择。假设这次选择Client3 Get 1,然而,明显这个时候执行Get得到应该是0,与该请求的实际执行结果返回1不同,此时,需要回退并尝试其他取出策略。可以看出WG算法其实是树的深度优先搜索,其搜索树如下图,其中每个节点标识的是本次尝试序列化的请求对应的调用历史中的Invoke序号:
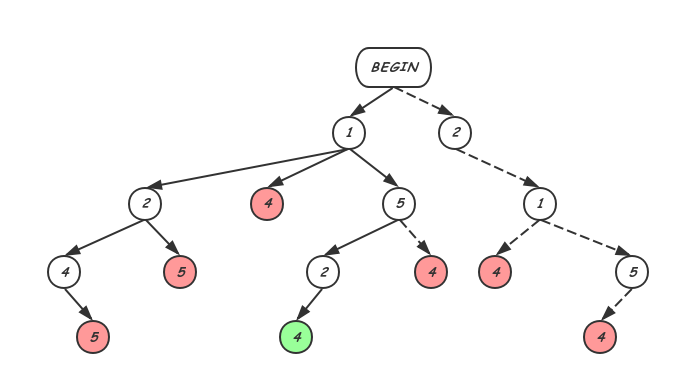
由于找到一个线性序列便可以停止,因此其中虚线部分是不会被实际执行的。
2,WGL算法
WGL算法由Gavin Lowe在WG算法的基础上进行改进,其改进的方式主要是对搜索树的剪枝:通过缓存已经见过的配置,来减少重复的搜索。缓存配置有两部分组成:
- 当前已经序列化的请求
- 当前x值
由上面的搜索过程可知,如果当前序列化的请求和当前的x值完全相同,则后续的搜索过程一定一致,因此可以略过。
3,P-compositionality算法
P-compositionality算法利用了线性一致性的Locality原理,即如果一个调用历史的所有子历史都满足线性一致性,那么这个历史本身也满足线性一致性。因此,可以将一些不相关的历史划分开来,形成多个规模更小的子历史,转而验证这些子历史的线性一致性,例如kv数据结构中对不同key的操作。上面提到了算法的计算时间随着历史规模的增加急速膨胀,P-compositionality相当于用分治的办法来降低历史规模,这种方法在可以划分子问题的场景下会非常有用。
为什么Solitaire
工程实践中,不只分布式系统,还包括需要并行访问的系统,都可能需要验证系统对外暴露的线性一致性功能。当然也有不少验证线性一致性的工具,比如大名鼎鼎的Jespen使用的Knossos,是一个Clojure版本的WGL的算法实现;Porcupine是一个Go版本的P-compositionality实现;linearizability-checker是P-compositionality算法作者自己实现的一个样例。但使用中还有几个问题没有解决:
- 计算速度慢:由于上面提到的复杂度,一致性算法验证时间通常是相关测试中的瓶颈。尽可能的加快其计算速度,可以在相同时间内验证更多的历史,对发现系统中的潜在问题至关重要。
- 数据模型单一:大多数的验证工具面向的都是KV接口,这就要求使用者将千差万别的系统实际接口转化为KV接口使用,而这层转换会掩盖系统中的众多复杂性,比如将Device接口转化为KV后会丢失对相互覆盖操作的验证。
- 具体问题具体分析:对一些数据模型来说,可能存在多项式甚至是线性复杂度的算法,那么针对这些数据模型使用通用的WGL算法就舍近求远了。
Solitaire是一个C++实现,更快速,支持多数据模型的线性一致性检测工具,致力于解决上述问题。其命名来源于上世纪著名的Windows桌面纸牌游戏,要求玩家在保证大小先序关系的限制下,将打乱的扑克牌整理为有序。可以说与我们的线性一致性验证工作非常契合了。
参考
- Linearizability: A Correctness Condition for Concurrent Objects
- Testing for Linearizability
- Faster linearizability checking via P -compositionality
- Testing Distributed Systems for Linearizability
- Testing Shared Memories
- 线性一致性理论
- Solitaire: 一个更快的,适配更多数据模型的一致性验证工具
- knossos: Jespen所使用的一致性验证工具,WGL算法实现
- porcupine: go版本P-compositionality算法实现
- linearizability-checker: P-compositionality算法实现
- Jespen