庖丁解LevelDB之版本控制
版本控制或元信息管理,是LevelDB中比较重要的内容。本文首先介绍其在整个LevelDB中不可替代的作用;之后从代码结构引出其实现方式;最后由几个主要的功能点入手详细介绍元信息管理是如何提供不可或缺的支撑的。
作用
通过之前的博客,我们已经了解到了LevelDB整个的工作过程以及从Memtable,Log到SST文件的存储方式。那么问题来了,LevelDB如何能够知道每一层有哪些SST文件;如何快速的定位某条数据所在的SST文件;重启后又是如何恢复到之前的状态的,等等这些关键的问题都需要依赖元信息管理模块。对其维护的信息及所起的作用简要概括如下:
- 记录Compaction相关信息,使得Compaction过程能在需要的时候被触发;
- 维护SST文件索引信息及层次信息,为整个LevelDB的读、写、Compaction提供数据结构支持;
- 负责元信息数据的持久化,使得整个库可以从进程重启或机器宕机中恢复到正确的状态;
- 记录LogNumber,Sequence,下一个SST文件编号等状态信息;
- 以版本的方式维护元信息,使得Leveldb内部或外部用户可以以快照的方式使用文件和数据。
下面就将更详细的进行说明。
实现
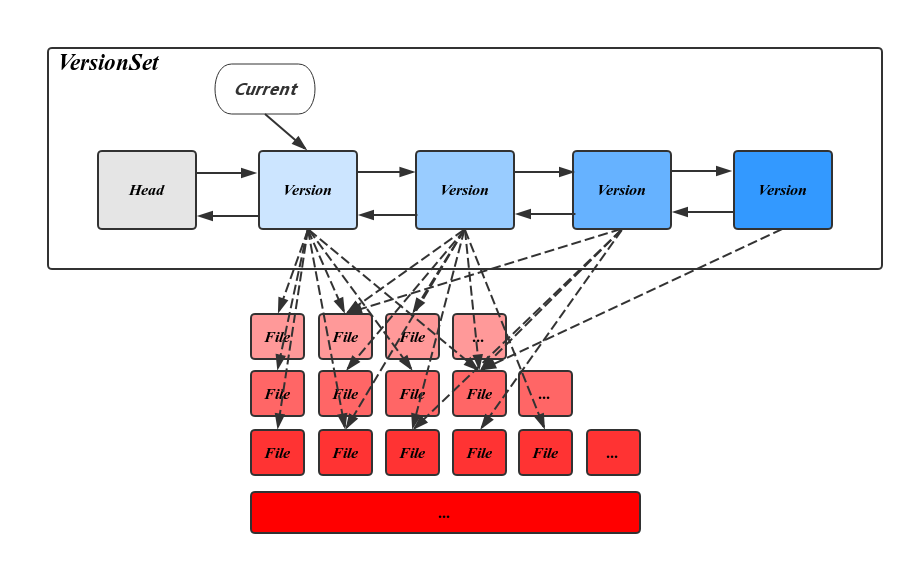
LeveDB用Version表示一个版本的元信息,Version中主要包括一个FileMetaData指针的二维数组,分层记录了所有的SST文件信息。FileMetaData数据结构用来维护一个文件的元信息,包括文件大小,文件编号,最大最小值,引用计数等,其中引用计数记录了被不同的Version引用的个数,保证被引用中的文件不会被删除。除此之外,Version中还记录了触发Compaction相关的状态信息,这些信息会在读写请求或Compaction过程中被更新。通过庖丁解LevelDB之概览中对Compaction过程的描述可以知道在CompactMemTable和BackgroundCompaction过程中会导致新文件的产生和旧文件的删除。每当这个时候都会有一个新的对应的Version生成,并插入VersionSet链表头部。
VersionSet是一个Version构成的双向链表,这些Version按时间顺序先后产生,记录了当时的元信息,链表头指向当前最新的Version,同时维护了每个Version的引用计数,被引用中的Version不会被删除,其对应的SST文件也因此得以保留,通过这种方式,使得LevelDB可以在一个稳定的快照视图上访问文件。VersionSet中除了Version的双向链表外还会记录一些如LogNumber,Sequence,下一个SST文件编号的状态信息。
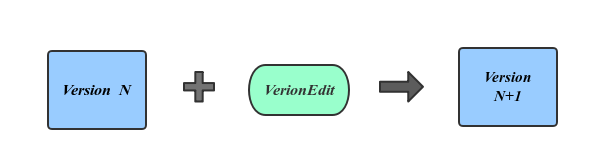
通过上面的描述可以看出,相邻Version之间的不同仅仅是一些文件被删除另一些文件被删除。也就是说将文件变动应用在旧的Version上可以得到新的Version,这也就是Version产生的方式。LevelDB用VersionEdit来表示这种相邻Version的差值。
为了避免进程崩溃或机器宕机导致的数据丢失,LevelDB需要将元信息数据持久化到磁盘,承担这个任务的就是Manifest文件。可以看出每当有新的Version产生都需要更新Manifest,很自然的发现这个新增数据正好对应于VersionEdit内容,也就是说Manifest文件记录的是一组VersionEdit值,在Manifest中的一次增量内容称作一个Block,其内容如下:
Manifest Block := N * Item
Item := [kComparator] comparator
or [kLogNumber] 64位log_number
or [kPrevLogNumber] 64位pre_log_number
or [kNextFileNumber] 64位next_file_number_
or [kLastSequence] 64位last_sequence_
or [kCompactPointer] 32位level + 变长的key
or [kDeletedFile] 32位level + 64位文件号
or [kNewFile] 32位level + 64位 文件号 + 64位文件长度 + smallest key + largest key
可以看出恢复元信息的过程也变成了依次应用VersionEdit的过程,这个过程中有大量的中间Version产生,但这些并不是我们所需要的。LevelDB引入VersionSet::Builder来避免这种中间变量,方法是先将所有的VersoinEdit内容整理到VersionBuilder中,然后一次应用产生最终的Version,这种实现上的优化如下图所示:
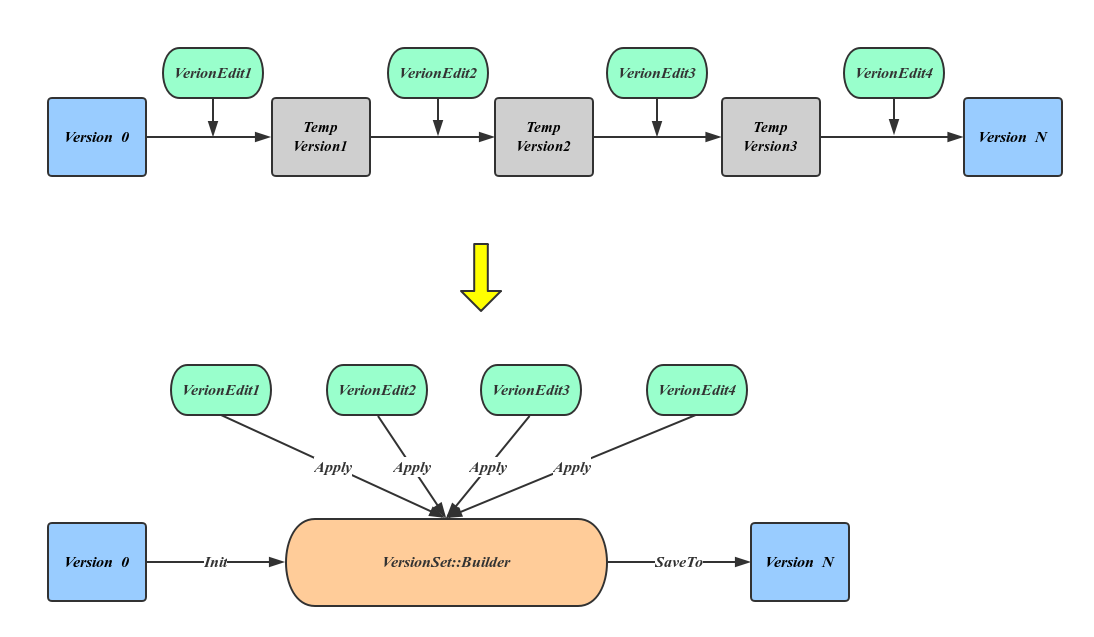
在这一节中,我们依次看到了LevelDB版本控制中比较重要的几个角色:Version、FileMetaData、VersionSet、VersionEdit、Manifest和Version::Builder。同时了解了他们各自的作用。接下来就一起从LevelDB主要的功能点中欣赏下他们的英姿。
功能点
版本控制中维护的各种元信息,为LevelDB的各个工作流程中提供了必不可少的支持:
1,Get
我们已经知道,LevelDB尝试获取某个Key的值时会依次尝试从Memtable,Immutable,SST文件中读取。一旦需要从SST文件中读取,就需要解决从大量文件中快速定位文件的问题。正是由于Version中记录了当前每个文件的最大最小值,使得这个问题变成比较Key值与文件的Key Range的过程。
我们已经知道,LevelDB的写操作会直接写入Memtable并通过异步的Compaction过程写入到不同层次的SST文件中,因此,上层文件拥有较新的数据,利用这个特征,LevelDB的Get接口会由上至下的依次从每一层中尝试查找,一旦查找成功,便可以忽略下层的相同Key的记录。
Level0层比较特殊,文件之间相互重叠无序,需要由新到旧的尝试从每个文件中查找。其他Level,由于SST文件本身有序排列,因此可以利用二分查找快速定位Key所在文件。找到Key值所在文件后,再用庖丁解LevelDB之数据存储中介绍的格式读取文件中内容。
2,Compaction触发时机
我们已经知道,LevelDB中会有后台线程来执行Compaction的操作,将上层文件与下层文件归并生成新的下层文件。Version中记录的各层的文件信息来帮助决定进行Compaction的时机:
- 容量触发Compaction:每个Version在其生成的时候会初始化两个值compaction_level_、compaction_score_,记录了当前Version最需要进行Compaction的Level,以及其需要进行Compaction的紧迫程度,score大于1被认为是需要马上执行的。我们知道每次文件信息的改变都会生成新的Version,所以每个Version对应的这两个值初始化后不会再改变。level0层compaction_score_与文件数相关,其他level的则与当前层的文件总大小相关。这种区分的必要性也是显而易见的:每次Get操作都需要从level0层的每个文件中尝试查找,因此控制level0的文件数是很有必要的。同时Version中会记录每层上次Compaction结束后的最大Key值compact_pointer_,下一次触发自动Compaction会从这个Key开始。容量触发的优先级高于下面将要提到的Seek触发。
- Seek触发Compaction:Version中会记录file_to_compact_和file_to_compact_level_,这两个值会在Get操作每次尝试从文件中查找时更新。LevelDB认为每次查找同样会消耗IO,这个消耗在达到一定数量可以抵消一次Compaction操作消耗的IO,所以对Seek较多的文件应该主动触发一次Compaction。但在引入布隆过滤器后,这种查找消耗的IO就会变得微不足道了,因此由Seek触发的Compaction其实也就变得没有必要了。
- 手动Compaction:LevelDB提供了外部接口CompactRange,用户可以指定触发某个Key Range的Compaction,LevelDB默认手动Compaction的优先级高于两种自动触发。
3,构造Compaction:
达到触发条件进行Compaction操作时,会首先通过Version来构造所有本次Compaction所需要的信息,记录在Compaction对象中,包括发生Compaction的level,所有参与的level和level+1层的文件信息,level+2层的文件信息等。 下面针对自动触发Compaction的情况介绍,手动Compaction的过程大体类似,这个过程叫做PickCompaction。
- 获得要Compaction的一个文件加入input_[0],容量触发时这个文件由compaction_level_加compact_pointer_确定,否则由file_to_compact_level_和file_to_compact_确定。对于level0,由于其文件相互重合,需要将所有与当前Compaction文件重合的文件全部加入input_[0]。
- 获得所有与level[0]有Key Range重合的level+1层文件加入input_[1],可以看出所有input_[1]文件的Key Range可能大于level[0],为了减少LevelDB整体Compaction次数,LevelDB会在不增加input_[1]文件数的前提下尝试增加level[0]文件数来扩大level层文件的Key Range。
- 获得所有与当前Key Range重合的level+2层文件加入input_[2],这里记录level+2层的文件信息是为了Compaction生成新的level+1层文件时,保证新文件不会与level+2中太多的文件有Key Range的重合,从而导致以后该文件的Compaction有太大的Merge开销,这个信息会在生成新文件的过程中不断检查。
- 生成归并Iterator,接下来就是用上面收集的信息生成归并Iterator,之后遍历这个Iterator生成新的文件,Iterator相关的内容会在之后一篇博客详细介绍。
4,Version持久化:
Compaction过程会造成文件的增加和删除,这就需要生成新的Version,上面提到的Compaction对象包含本次Compaction所对应的VersionEdit,Compaction结束后这个VersionEdit会被用来构造新的VersionSet中的Version。同时为了数据安全,这个VersionEdit会被Append写入到Manifest中。在库重启时,会首先尝试从Manifest中恢复出当前的元信息状态,过程如下:
- 依次读取Manifest文件中的每一个Block, 将从文件中读出的Record反序列化为VersionEdit;
- 将每一个的VersionEdit Apply到VersionSet::Builder中,之后从VersionSet::Builder的信息中生成Version;
- 计算compaction_level_、compaction_score_;
- 将新生成的Version挂到VersionSet中,并初始化VersionSet的manifest_file_number_, next_file_number_,last_sequence_,log_number_,prev_log_number_ 信息;
总结
版本控制或元信息管理,在LevelDB的各个流程中穿针引线,保证了整个数据库的正确稳定,不可或缺。接下来的一篇博客将着重介绍,在LevelDB中出镜率极高又十分优雅的Iterator。
参考
Source Code:https://github.com/google/leveldb
庖丁解LevelDB之概览: http://catkang.github.io/2017/01/07/leveldb-summary.html
庖丁解LevelDB之数据管理: http://catkang.github.io/2017/01/07/leveldb-summary.html