Raft和它的三个子问题
这篇文章来源于一个经常有人困惑的问题:Quorum与Paxos,Raft等一致性协议有什么区别,这个问题的答案本身很简单:一致性协议大多使用了Quorum机制,但仅仅有Quorum(R+W>N)机制是保证不了一致性的。本文计划延伸这个问题,以Raft为例回答一个完善的一致性协议拥有包括Quorum在内的那些机制,试着说明这些机制的完备以及其中每一项的不可或缺。
一致性
要回答这个问题首先需要说明Raft是做什么的,Paxos、Raft被称为一致性协议,顾名思义它们要解决的是多节点的一致性问题,需要注意的是这里所说的一致性并不是要求所有节点在任何时刻状态完全一致。而是要保证:
即使发生网络分区或机器节点异常,整个集群依然能够像单机一样提供一致的服务,即在每次操作时都可以看到其之前的所有成功操作按顺序完成。
这里有两点需要说明:
- 强调在网络分区或节点异常时,是因为如果不考虑这种异常状况,一致性是非常容易保证的,单节点即可。而一致性协议所要做的就是在容忍异常的情况下保证一致。
- 这里的一致是对集群外部使用者而言的,将整个集群看做一个整体。
将每一个对Raft集群的操作称为一个提案,希望Raft集群对外屏蔽内部的网络或节点异常,依次对每一个提案作出响应,提交成功的提案可以在后续操作中持续可见。这里的提案需要是幂等的,即重复执行不会导致集群状态不同。
接下来我们就看Raft是如何实现这种一致性保证的。Raft将一致性问题拆分为三个子问题,各个击破,从而使得其实现简单易懂。本文将首先简单介绍其三个子问题的内容以及达成方式;之后证明三个子问题是实现一致性的充分条件;最后尝试说明这三个子问题的保证缺一不可。
Raft的子问题
1. Leader Election
组成一个Raft集群至少需要三台机器,而Raft限制每一时刻最多只能有一个节点可以发起提案,这个限制极大的简化了一致性的实现,这个可以发起提案的节点称为Leader。因此所要解决的第一个问题便是:
- 如何保证任何时候最多只有一个Leader节点
- 以及当Leader节点异常时如何尽快的选择出新的Leader节点。
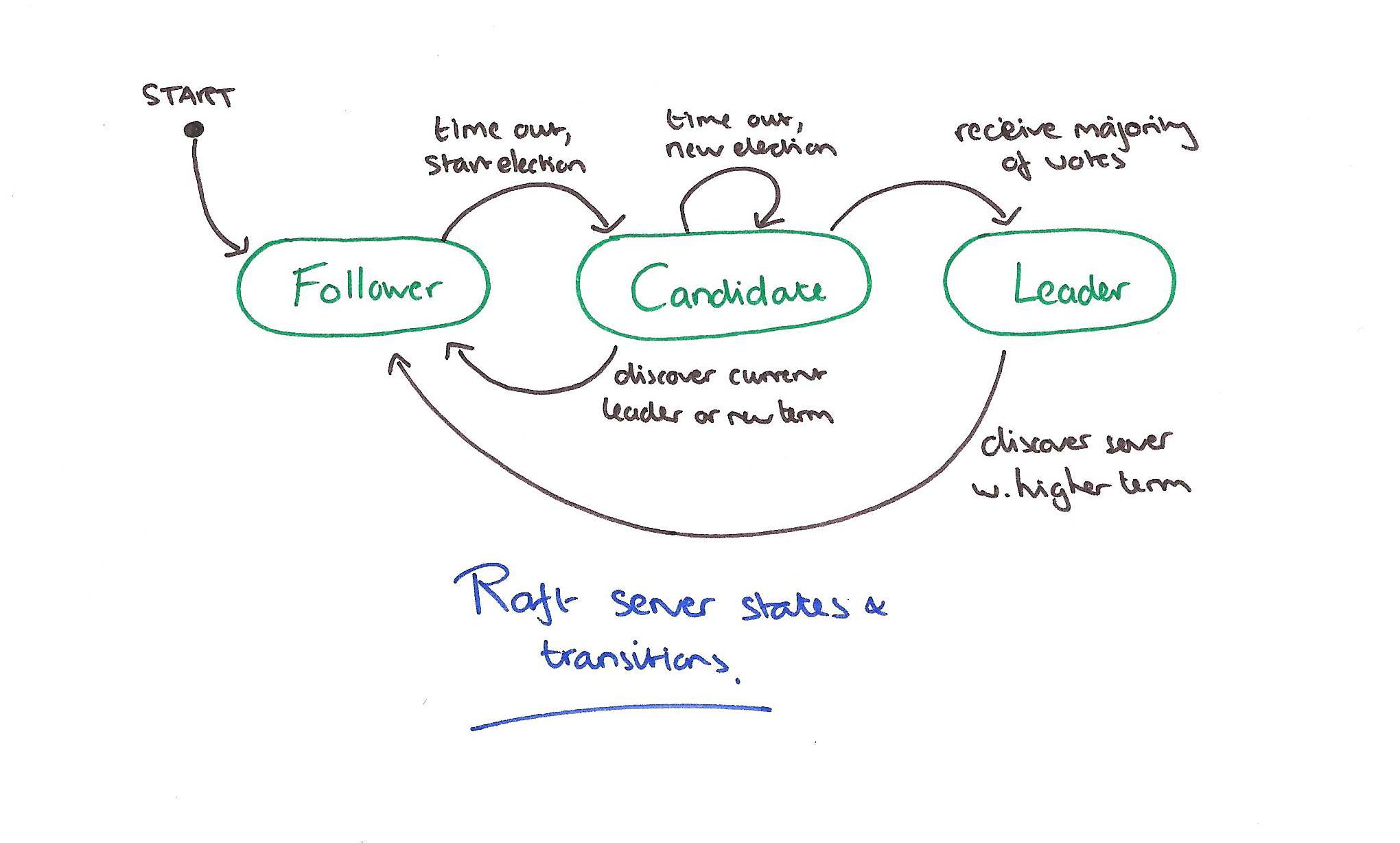
如上图所示:
- 所有的节点以Follower的角色启动;
- Leader周期性给其他节点发送心跳;
- 在超时时间内没有收到心跳包的Follower变成Candidate,将自己的Term加一,并广播Vote请求,发起新一轮选举;
- 选举结束:
- 收到大多数节点的投票,变成Leader,并向其他节点发送自己Term的AppendEntry。在一个Term里,同一个Server只会给出一次投票,先到先得;
- 收到相同或更大Term的AppendEntry,承认对方为Leader,变成Follower;
- 超时,重新开始新的选举,通过随机的超时时间来减少这种情况得发生。
2. Log Replication
从上面对Raft状态转换的讨论中可以看到,任何非Leader的节点都有可能在未来成为Leader,为了能保证后续Leader节点变化后依然能够使得整个集群对外保持一致,需要通过Log Replication机制来解决如下两个问题:
- Follower以与Leader节点相同的顺序依次执行每个成功提案;
- 每个成功提交的提案必须有足够多的成功副本,来保证后续的访问一致
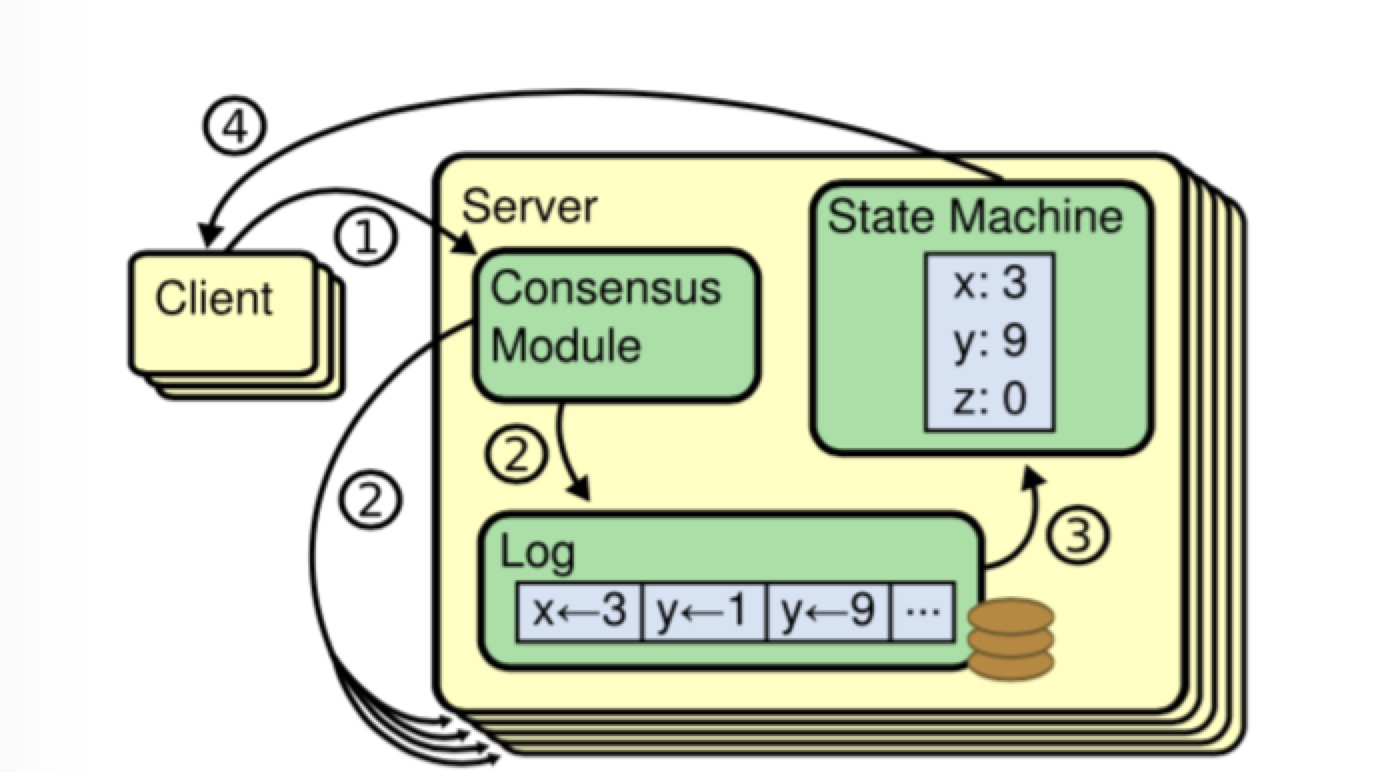
上图描述了一个Raft提案的执行过程:
- Leader收到Client的请求,写入本地Log,之后并行地向所有Follower通过AppendEntry请求发送该Log Entry;
- Follower对收到的Entry进行验证,包括验证其之前的一条Log Entry项是不是和Leader相同,验证成功后写入本地Log并返回Leader成功;
- Leader收到超过半数的Follower答复成功后,将当前Log Commit(如写入状态机),之后返回客户端成功;
- 后续的AppendEntry及HeartBeat都会携带主的Commit位置,Follower会提交该位置之前的所有Log Entry。
Follower在接受AppendEntry时会检查其前一条的Log是否与Leader相同,利用数学归纳法可以很简单的证明Leader和Follower上的Log一致。另外,由于只需要过半数的节点成功即可返回,也就在保证一致性的前提下竟可能的提高了集群的可用性。
W > N/2 & R > N/2 => W + R > N
这里需要注意,Leader Commit过的提案会向用户返回成功,因此Raft集群需要保证这些提案永远存在。
3. Safety
通过上述的两个子问题已经解决了大部分的难题,除了下面两个细节:
- Leader Crash后,新的节点成为Leader,为了不让数据丢失,我们希望新Leader包含所有已经Commit的Entry。为了避免数据从Follower到Leader的反向流动带来的复杂性,Raft限制新Leader一定是当前Log最新的节点,即其拥有最多最大term的Log Entry。
- 通常对Log的Commit方式都是Leader统计成功AppendEntry的节点是否过半数。在节点频发Crash的场景下只有旧Leader Commit的Log Entry可能会被后续的Leader用不同的Log Entry覆盖,从而导致数据丢失。造成这种错误的根本原因是Leader在Commit后突然Crash,拥有这条Entry的节点并不一定能在之后的选主中胜出。这种情况在论文中有详细的介绍。Raft很巧妙的限制Leader只能对自己本Term的提案采用统计大多数的方式Commit,而旧Term的提案则利用“Commit的Log之前的所有Log都顺序Commit”的机制来提交,从而解决了这个问题。另一篇博客中针对这个问题有更详细的阐述Why Raft never commits log entries from previous terms directly
子问题的充分性
通过上述的三个子问题的解决,我们得到了一个完善的一致性算法,论文中给出了详细严谨的证明,其首先假设Commit过的提案会在后续丢失,之后推导出矛盾进而反证成功,这里不再赘述。该证明的关键点在于:Leader Election中要求新Leader获得超过半数的节点投票,Log Replication中每个Commit都有超过半数的节点同意,因此这两个大多数中至少存在一个公共节点,这个节点既同意了某个提案的Commit又投票给了新的Leader。
子问题的不可或缺
上面讨论了三个子问题对一致性的充分性,接下来要讨论的是在Raft的框架下,任何一个子问题的缺失都会导致严重的不一致后果:
- Leader Election缺失,假设某一时刻有两个节点作为Leader同时接受用户请求,发起提案。整个集群便无法确定这两个提案的前后关系,从而导致冲突。Dynamo虽然使用了Quorum的写入策略却依然需要通过vector clock甚至交给用户来处理冲突。
- Log Replication缺失,假设提案的提交不能保证R + W > N,也就是读写两次提交涉及的节点之间可能没有交集。显而易见的会导致成功提交的请求在后续访问中不可见。
- Safety缺失,假设新Leader不能保证拥有最长的Log,其可能并没有最新的Commit数据,从而导致之前成功的提交不可见;
通过上面的讨论,可以看出一个完整的一致性协议做了包括Quorum在内的诸多努力。Raft划分了三个子问题来使得整个一致性算法的实现简单易懂,我们也基于Raft实现了自己的一致性库Floyd来满足诸如Zeppelin元信息集群及Pika跨机房功能中对一致性的需求。