LSM upon SSD
近年来,以LevelDB和Rocksdb为代表的LSM(Log-Structured Merge-Tree)存储引擎凭借其优异的写性能及不俗的读性能成为众多分布式组件的存储基石,包括我们近两年开发的类Redis大容量存储Pika和分布式KV存储Zeppelin,在享受LSM的高效的同时也开始逐渐体会到它的不足,比如它在大Value场景下的差强人意以及对磁盘的反复擦写。正如之前的博客庖丁解LevelDB之概览中已经介绍了的LevelDB的设计思路,其最大的优势便是将磁盘的随机写转化为顺序写,但随着在系统中越来越多的使用SSD,这种设计是否仍然能带来如此大的收益,在SSD统治的世界里是否有更合理的存储结构。
2016年,FAST会议发表了论文WiscKey: Separating Keys from Valuesin SSD-conscious Storage,阐述了一种对SSD更友好的基于LSM的引擎设计方案。
问题
大家知道,LSM Tree是一种对写优化的系统,将随机写转化为顺序写,从而获得非常优秀的写性能,但一定的LSM也损失了一些东西作为交换,这个损失就是写放大,即实际的磁盘写跟用户请求写的比值,就是说:
LSM Tree 将随机写转化为顺序写,而作为代价带来了大量的重复写入
那么这种交换是否值得呢,先来看损失,以LevelDB为例,在最坏的情况下:
- 写放大:10 * Level(Level N-1向Level N的Compact可能涉及多达10个Level N-1层文件)
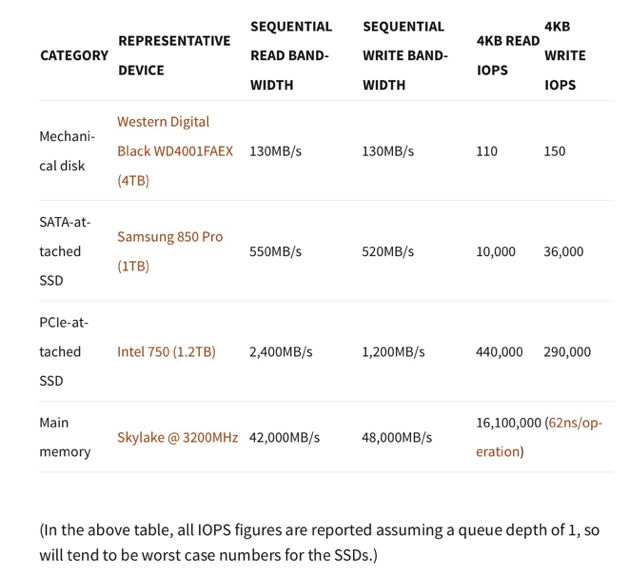
也就是说,这个写放大的系数大概在几十到几百之间。那么收获的呢,通过下表中针对不同存储介质的写入测试数据,可以看出在传统的机械盘上顺序写的性能远远好于其随机写性能,这个性能差异接近一千倍。用数十倍的磁盘带宽损失换取近千倍的性能提升,在写入敏感的场景下这种交换的效果毋庸置疑。但不同的是,SSD盘相对具有较高的随机写能力,与顺序写的差距本身只有十倍左右,并且还可以通过并行IO进一步提升,因此这种交换就显得有些得不偿失。同时,由于反复的写入会带来SSD的磨损从而降低寿命。
思路
回顾上面的问题,当LSM中数据的长度很大时,这个问题变得尤为突出,这是因为:
- 数据长度越大,越容易触发Compaction,从而造成写放大;
- 如果把上层文件看做下层文件的cache,大数据长度会造成这个cache能cache的数据个数变少,从而读请求更大概率的需要访问下层数据,从而造成读放大;
- 每条数据每次Merge需要更多的写入量
进一步分析,LSM需要的其实是key的有序,而跟value无关。所以自然而然的思路是:
Key Value 分离存储
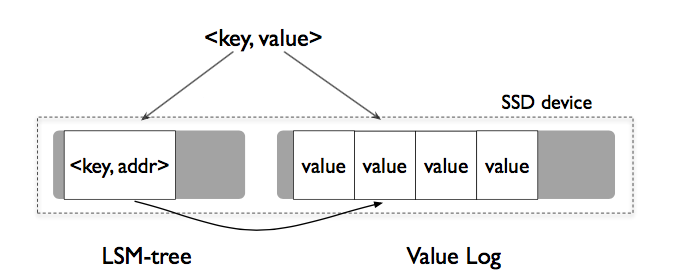
仅将Key值存储在LSM中,而将Value区分存储在Log中,数据访问就变成了:
- 修改:先append到vLog末尾,再将Key,Value地址插入LSM
- 删除:直接从LSM中删除,无效Value交给之后的垃圾回收
- 查询:LSM中获得地址,vLog中读取
这样带来显而易见的好处:
- 避免了归并时无效的value而移动,从而极大的降低了读写放大
- 显著减少了LSM的大小,以获得更好的cache效果
挑战
这种思路是否可行呢,分析可知,Key Value分开存储会导致以下三种问题,如果能解决或者容忍,那么这种设计就是成功的。
1,Key Value分离带来的Range操作的低效
由于Key Value的分离,Range操作从顺序读变成了顺序读加多次随机读,从而变得低效。利用SSD并行IO的能力,可以将这种损失尽量抵消,这正是得益于SSD较强的随机访问性能。
2,被用户删除或者过期版本的Value的空间回收
Compaction过程需要被删除的数据由于只是删除了Key,Value还保留在分开的Log中,这就需要异步的回收。可以看出LSM本身的Compaction其实也是垃圾回收的思路,所以通过良好设计的Value回收方式其实并不会过多的增加系统的额外负担。离线回收比较简单,扫描整个LSM对Value Log进行mark and sweep,但这相当于给系统带来了负载带来了陡峭的波峰,WiscKey论文又提出来了巧妙的在线回收方式:
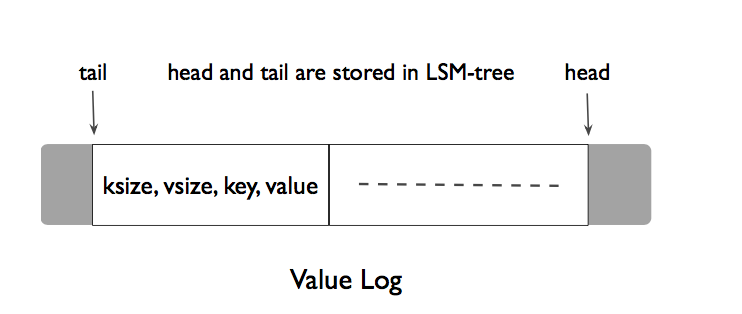
其中head的位置是新的Block插入的位置,tail是Value回收操作的开始位置,垃圾回收过程被触发后,顺序从Tail开始读取Block,将有效的Block插入到Head。删除空间并后移Tail。可以看出,这里的回收方式由于需要将有效的数据重新Append,其实也带来了写放大,这就需要很好的权衡空间放大和写放大了,WiscKey建议系统根据删除修改请求的多少决定触发垃圾回收的时机。
3,Crash Consistency
正式由于Key,Value的分离带来了不可避免的在程序Crash发生时不一致的情况,WiscKey需要像标准的LSM一样提供如下保证:
- key-value的原子性:要成功都成功,要失败都失败
- 重启后的顺序恢复
WicsKey给出的解决方案,是在启动时对Key, Value进行检查:
- Key成功写入,Value没有,则从LSM中删除Key,并返回不存在
- Key没有成功写入,Value写入,返回不存在,并在后续的垃圾回收中清楚Value。
优化
- Value-Log Write Buffer: 给vLog维护一个缓存,来将短value合并为长value来提高磁盘吞吐
- Optimizing the LSM-tree Log:去掉LSM的Log,并周期性的更新Value Log的head值进LSM。crash后的恢复仅需要从head开始遍历所有的vLog同样能保证上面提到的Crash Consistency
总结
通过上面的介绍,可以看出WiscKey并不是一个全方位的解决方案,其不得不面对Key Value分离带来的不一致和处理效率的下降,这种增加的负担会在小Value的场景下尤为明显。所以WiscKey针对的仅仅是Value长度远远大于Key的情况。我们的Zeppelin向上支持的S3需求很契合这样一种场景,所以WiscKey也是我们未来在引擎层的一种发展方向。
最后抒情一下,WiscKey不完美,但他启示我们在硬件更替的现在,人们做到的还远远不够,还有更多的潜力和宝藏等待去发掘,属于LevelDB和RocksDB的容光可能会逐渐褪去,但人类对更好的存储的追求永不停歇,而我们工程师所要做的就是追逐先行者的脚步,搭建起连接未来和现实的桥梁。
参考
WiscKey: Separating Keys from Valuesin SSD-conscious Storage