Zeppelin不是飞艇之元信息节点
从Zeppelin不是飞艇之概述的介绍中我们知道元信息节点Meta以集群的形式向整个Zeppelin提供元信息的维护和提供服务。可以说Meta集群是Zeppelin的大脑,是所有元信息变化的发起者。每个Meta节点包含一个Floyd实例,从而也是Floyd的一个节点,Meta集群依赖Floyd提供一致性的内容读写。本文将从角色、线程模型、数据结构、选主与分布式锁、集群扩容缩容及成员变化几个方面详细介绍,最后总结在Meta节点的设计开发过程中带来的启发。
角色
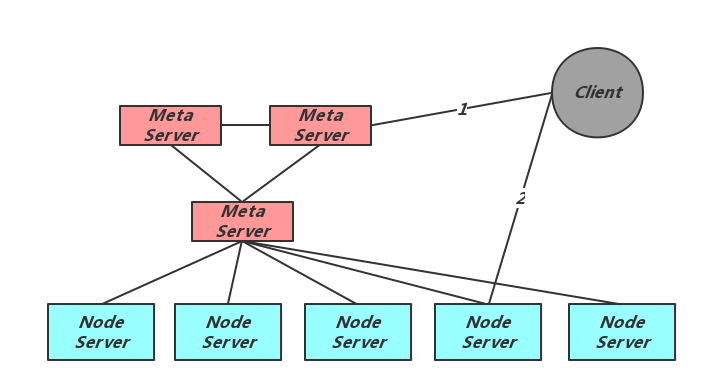
从上图可以看出Meta集群的中心地位:
- 向Client及Node Server提供当前的元信息,包括分片副本信息,Meta集群成员信息等;
- 保持与Node Server的心跳检测,发现异常时进行切主;
- 接受并执行运维命令,完成相应的元信息变化,包括扩容、缩容、创建Table、删除Table等;
线程模型
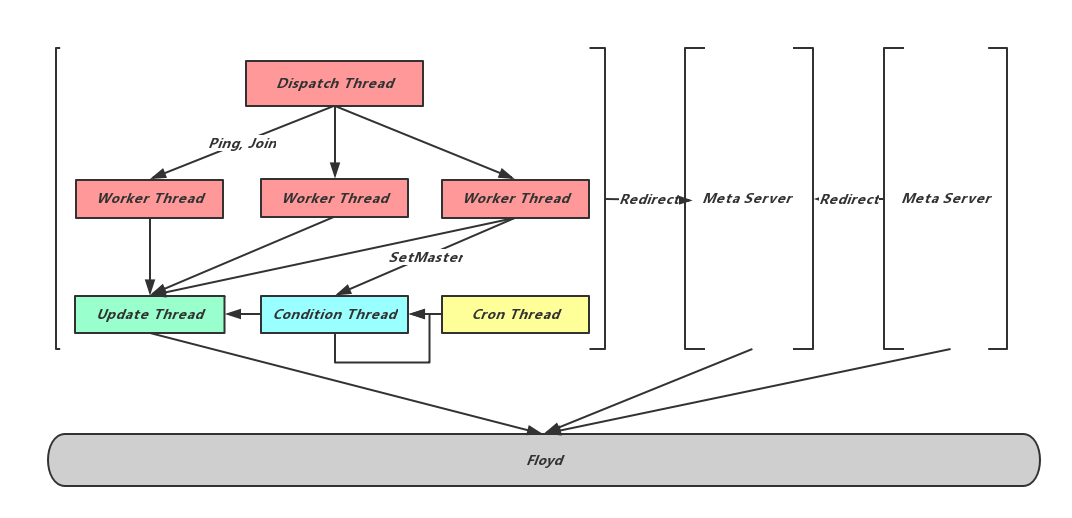
相对于存储节点,元信息节点的线程模型比较简单:
- 处理请求的Dispatch线程和Worker线程;
- 修改Floyd的Update线程,Update线程是唯一的Floyd修改者。所有的元信息修改需求都会通过任务队列转交给Update线程。同时为了减轻Floyd的写入压力,这里采用了延时批量提交的方式;
- Condition线程用来等待Offset条件,一些元信息修改操作如SetMaster,扩容及缩容,需要等到分片副本的主从Binlog Offset追齐时才能执行,Meta从与Node之间的心跳中得到Offset信息,Condition线程不断的检查主从的Offset差距,仅当追齐时通知Update线程完成对应修改;
- Cron线程执行定时任务,包括检查和完成Meta主从切换、检查Node存活、Follower Meta加载当前元信息、执行数据迁移任务等。
数据结构
为了完成上述任务,Meta节点需要维护一套完整的数据,包括Node节点心跳信息、Node节点Offset信息、分片信息、Meta成员信息、扩容迁移信息等。由于一致性算法本身限制,我们需要尽量降低对Floyd的访问压力,因此并不是所有这些数据都需要直接维护在Floyd中。Zeppelin根据数据的重要程度、访问频率及是否可恢复进行划分,仅仅将低频访问且不易恢复的数据记录在Floyd中。
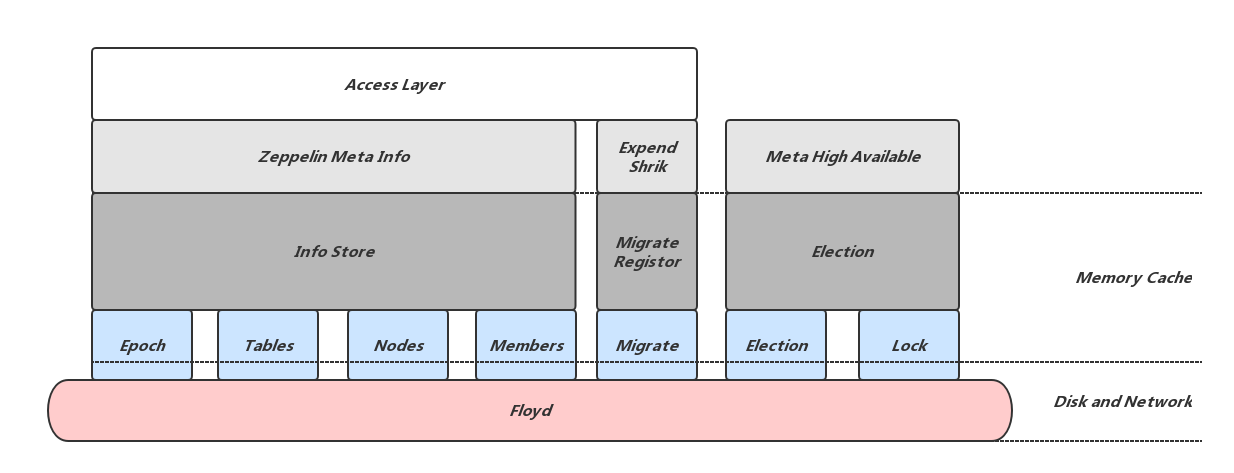
上图所示是Meta节点所维护数据的数据结构及存储方式,可以看出,除了一致性库Floyd中记录的数据外,Meta还会在内存中维护对应的数据结构,内存数据结构依赖Floyd中的数据,重新组织并提供更方便访问的接口。从所完成的任务来看,主要包括三个部分:
1,维护和提供集群元信息(Zeppelin Meta Info)
对应内存数据结构InfoStore,InfoStore依赖Floyd中的数据,包括:
- 当前元信息的版本号Epoch,每次元信息的变化都会对Epoch加一;
- 数据分片副本的分布及主从信息Tables;
- 存储节点地址及存活信息Nodes;
- Meta集群自己的成员信息Members;
InfoStore重新组织这些数据,对外提供方便的查询和修改接口;除此之外InfoStore还会维护一些频繁修改但可以恢复的数据:
- 存储节点上次心跳时间:宕机后丢失,可以通过Floyd中的Nodes信息及恢复时的当前时间恢复,注意这里使用恢复时的当前时间相当于延长的存储节点的存活;
- 存储节点的分片Binlog偏移信息:Meta需要这些信息来决定副本的主从切换,宕机恢复后可以从Node的心跳中获得,这也就要求Node在重新建立心跳连接后的第一个包需要携带全量的Binlog偏移信息。
2,扩容缩容相关的迁移信息(Epend Shrink)
对应内存数据结构MigrateRegister,负责迁移过程的注册和提供,这部分内容将在稍后的集群扩容、缩容章节中详细介绍。
3,实现Meta集群高可用(Meta High Available)
Meta以集群的方式提供服务,Leader节点完成写操作,Follower分担读压力,节点之间依赖Floyd保证一致,从而实现Meta集群的高可用。内存数据结构Election负责节点异常时的选主,依赖Floyd提供的Lock接口及其中的Election相关数据。这部分内容将在稍后的选主与分布式锁章节中详细介绍。
选主与分布式锁
Meta集群中的节点分为Leader和Follower两种角色:
- 所有的写操作及心跳都会重定向到Leader,Leader将需要修改Floyd的请求封装为Task,加入等待队列,批量延时的写入Floyd,并更新本地的内存数据结构。
- Follower定时检查Floyd中的元信息,如果变化则加载并修改本地内存数据结构,并对外提供元信息的查询操作。
因此我们需要一种机制来选主,并且每个Leader需要一个定长的租约时间,在租约时间内集群不会选择其他Meta节点作为新的Leader,相当于牺牲一定的可用性来优化读性能。选主问题是典型的分布式锁的应用,获得分布式锁的节点即为主。我们认为分布式锁是由三层相互独立的问题组成的,如下图左边所示,自下而上分别是一致性(Consistency),锁的实现(Lock)及锁的使用(Usage of Lock)。其中Consistency是为了高可用,Lock提供了互斥的加锁的机制,而Usage of Lock部分通常有两种实现:
-
严谨实现:加锁时返回Sequence,这个Sequence自增,获得锁的节点之后的所有操作的受体都必须检查这个Sequence以保证操作在锁的保护中;
-
简单实现:节点在尝试加锁时需要提供一个时间,锁服务保证这个时间内不将锁给其他节点。使用者需要自己保证所有的操作能在这个时间内完成。这个方法虽然不严谨但是非常简单易用,Zeppelin的Meta集群采用的正是这种方式。
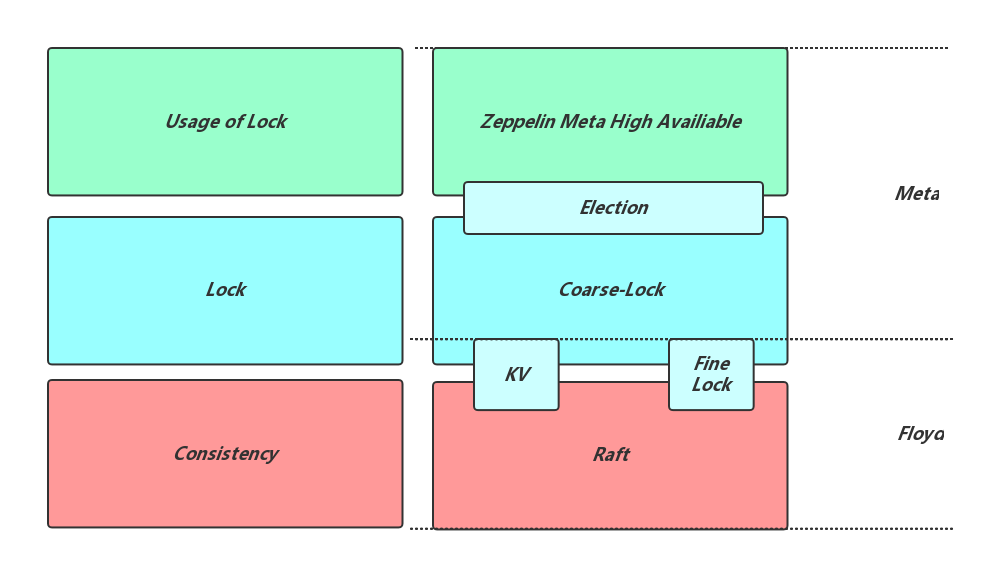
如上图右边部分显示了这三部分在Meta中的对应关系:
- Consistency我们依赖Floyd实现的Raft,同时Raft对外提供了细粒度的锁接口以及存储数据的Set、Get接口;
- 依赖Raft提供的接口,Meta实现了自己的粗粒度锁Coarse-Lock,简单的说,通过Set Get接口存储或查询当前Leader的地址信息及上次刷新时间;并通过Floyd的细粒度锁保护互斥的访问;Leader定时刷新自己的时间,Follower发现Leader超时后取而代之。Coarse-Lock层实现了Meta集群锁需要的Election。
- 利用Coarse-Lock,Meta实现了自己的高可用。Cron线程中不断触发当前节点检查并在需要的时候尝试选主。
这里需要说明的是,相对于Fine-Lock而言,Coarse-Lock加锁的时间更长,响应的锁的迁移也会带来更大的成本。比如主从链接的重新建立,任务队列的丢弃及清空,Meta工作线程的切换等。因此我们希望下层Lock抖动尽量不要影响上层的主从关系,针对这点Meta中设计了如下两种机制:
- Meta主从关系与Floyd主从关系解耦,即使Floyd主从变化,依然有可能对上层Meta集群透明;
- 引入Jeopardy阶段,正常运行过程中,Meta会记录当前的Leader信息,当Floyd由于网络或节点异常无法服务时,Meta层会进入Jeopardy阶段中,Jeopardy使得Meta节点在一定的时间内依然保持主从关系不变。这个时间就是上面提到的为了读优化给Leader的Lease。之所以能够这么做,正是由于Zeppline的设计中尽量减少对Meta集群作为中心节点的依zeppelin_meta/
集群扩容、缩容
Zeppelin作为存储集群,考虑到资源利用及业务变化,不可避免的需要进行集群的扩容、缩容或平衡操作。下图是简单的扩容操作示例,三个存储节点Node1,Node2,Node3,负责分片P1,P2,P3的九个主从副本。这时Node4加入,需要将P1的Master副本和P3的Slave副本迁移过去。
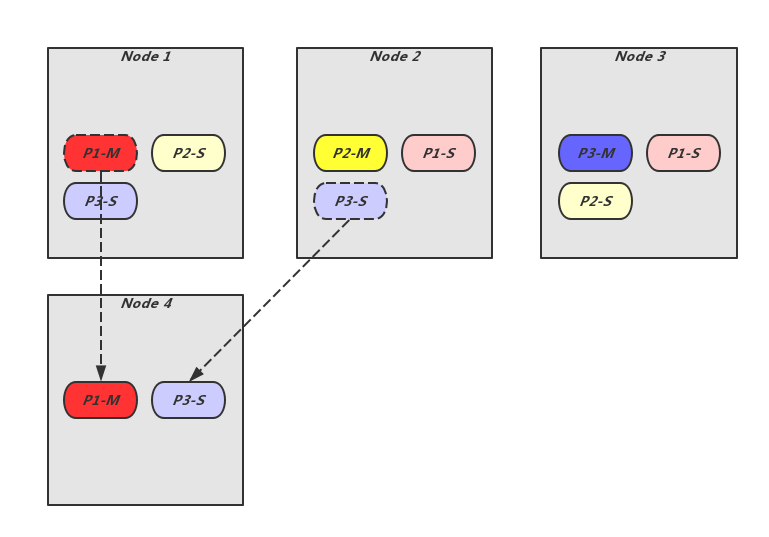
针对这类问题,主要有如下诉求:
- 持续时间可能很长,过程中无人工介入;
- 保证数据正确;
- 减少线上服务无感知;
- 不显著增大Meta负担,包括资源使用和代码复杂度;
- Meta节点异常或网络异常后可从断点恢复;
- 容忍Node状态变化;
- 方便暂停、取消,可以获取状态及当前进度;
- 负载均衡;
子问题
为了很好的解决这个问题,我们先进行子问题的推导及切割:
- 扩容、缩容及平衡,其实都是将多个分片从源节点移动到目的节点;
- 迁移一个分片,可以拆分为增加新的Slave分片,等待数据同步,切换并删除原分片三个步骤。
方案
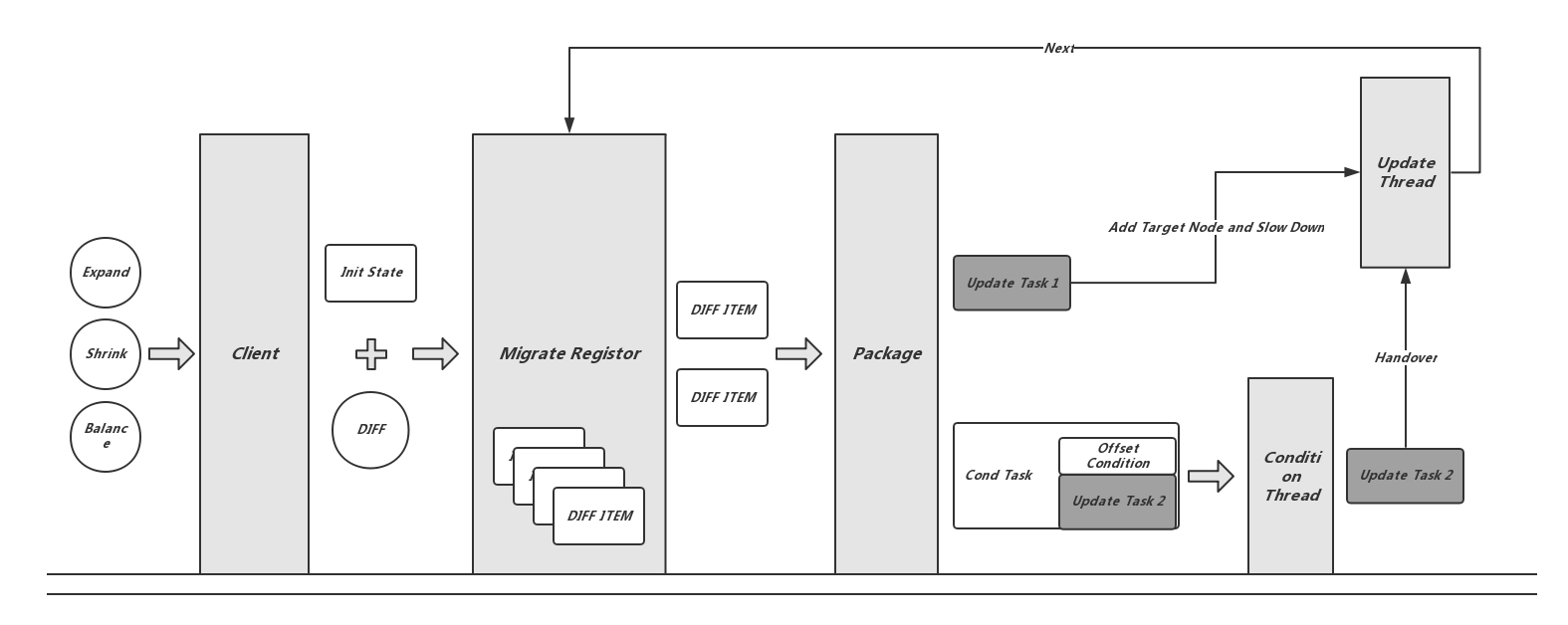
上图所示是Zeppelin的扩容、缩容及平衡机制:
- 客户端命令行工具中将扩容(Expand),缩容(Shrink)及平衡(Balance)操作,通过Zeppelin的数据分布算法DPRD转化为初始状态(Init State)和一组DIFF集合,每一个DIFF项指定一个分片副本及其要迁移的源节点、目的节点;
- Init State及DIFF集合传递给Meta Leader节点的Migrate Registor模块,检查Init State并将DIFF集合写入Floyd;
- Cron线程定时获取一定量的DIFF项,顺序执行每个DIFF项;
- 生成添加新的从副本的UpdateTask1交给Update线程尽快执行,同时设置状态将该分片缓写或阻写;
- 生成ConditionTask交给Condition线程,ConditionTask中包括一个Offset条件和一个切换副本的UpdateTask2,这个Offset条件通常指源节点和目的节点偏移量一致;
- Condition线程等待满足Offset条件后将对应的UpdateTask2交给Update线程尽快执行;
- 完成必要的状态改变后,将对应的DIFF项从Register中删除,并继续取出新的DIFF执行,直到全部完成。通过这种方式,任何时候Meta节点宕机,新Leader都可以从Floyd中获得DIFF并继续操作。
成员变化
通常Meta集群是一个3或5个节点的一致性集群,有时我们需要改变Meta集群的成员,增加、删除或替换。Meta集群的成员变化依赖下层的Floyd,Floyd提供每次一个节点变化的Membership Change方式,详细算法见CONSENSUS: BRIDGING THEORY AND PRACTICE。
Floyd的成员变化后,Meta集群对应修改自己的内存数据结构Membership,同时元信息Epoch加一,从而整个集群的Node及Client都能从新拉取的元信息中得知新的Membership。
Lessons We Learn
1,责任分散
将中心节点的责任分散到大量的Node和Client上,从而减轻对中心节点的依赖:
- 心跳:由Node发起并检查链接状态;
- 元信息提供:Node及Client发现主动拉去,而不是由Meta分发。同时Node还会在访问错误节点时,给Client返回kMove消息来帮助Client不通过Meta即可得到部分需要的元信息数据。
2,考虑扩展性时,减少通信次数有时候比优化单次请求处理速度更有效
3,限制资源的线性增长
比如,我们通过批量延迟提交Flody的方法,将一段时间以内的修改操作归并起来,变成一次对Floyd的访问。将请求数级别修改频次变为每秒常数次。
4,故障恢复时的数据恢复
同样为了减少Floyd的压力,我们不会将所有数据存储到Floyd中,那么有些只在内存中维护的数据就需要在服务恢复时恢复出来,恢复时的数据来源可以包括:
- 持久化数据(尽量少);
- 外部请求中携带,比如Node的Offset信息从心跳中恢复;
- 估计值,比如Meta中的Node存活时间是直接用恢复的当前时间的;
5,无重试可重入
Meta中的所有操作都是无重试可重入的,指所有步骤的失败不直接进行重试,而是做一些状态恢复后丢弃,依赖外部的二次操作来完成,也就要求所有的的操作都是可重入的,这样做带来的好处是:
- 处理清晰简单,所有发生错误的地方可以直接丢弃任务;
- 上层更好估计操作完成需要的时间,从而向分布式锁或Node作出时间上的保证。
参考
CONSENSUS: BRIDGING THEORY AND PRACTICE