Ceph Monitor的Paxos实现
Ceph Monitor作为Ceph服务中的元信息管理角色,肩负着提供高可用的集群配置的维护及提供责任。Ceph选择了实现自己的Multi-Paxos版本来保证Monitor集群对外提供一致性的服务。Ceph Multi-Paxos将上层的元数据修改当成一次提交扩散到整个集群,Ceph中简单的用Paxos来指代Multi-Paxos,我们也沿用这一指代。本文将介绍Ceph Paxos的算法细节,讨论其一致性选择,最后简略的介绍代码实现。本文的大部分信息来源于Ceph Monitor相关源码,若有偏颇或谬误,敬请指正。
算法介绍
概览
Paxos节点与Monitor节点绑定,每个Monitor启动一个Paxos。当有大多数的Paxos节点存活时集群可以运行,正常提供服务的过程中,一个节点做为Leader角色,其余为Peon角色。只有Leader可以发起提案,所有Peon角色根据本地历史选择接受或拒绝Leader的提案,并向Leader回复结果。Leader统计并提交超过半数Paxos节点接受的提案。
每个提案都是一组对Monitor元信息的修改操作,序列化后在Paxos层传递。Leader发起提案及Peon接受提案时都会写入本地Log,被提交的Log会最终写入DB,写入DB的提案才最终可见。实现中用同一个DB实例承载Log和最终数据的存储,并用命名空间进行区分。
除去上面提到的Leader及Peon外,Paxos节点还有可能处于Probing、Synchronizing、Election三种状态之一,如Figure 1所示。其中,Election用来选举新的Leader,Probing用来发现并更新集群节点信息,同时发现Paxos节点之间的数据差异,并在Synchronizing状态中进行数据的追齐。当Membership发生变化,发生消息超时或lease超时后节点会通过boostrap进入Probing状态,并向其他节点广播prob消息,所有收到prob消息的非prob或synchronizing节点会同样回到Probing状态。Probing状态收到过半数的对Members的认可后进入Election状态。同时Probing中发现数据差距过大的节点会进入synchronizing状态进行同步或部分同步。更多的内容会在稍后的Recovery,Membership及Log Compaction中介绍。
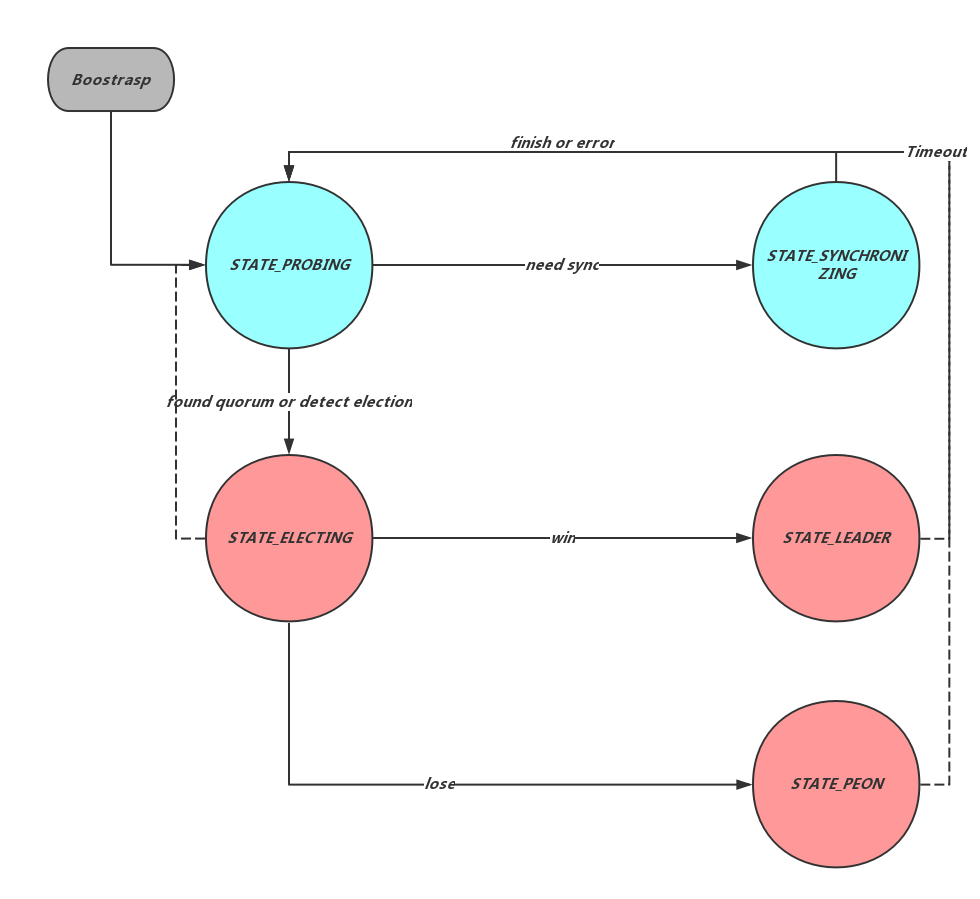
Leader会向所有Peon发送Lease消息,收到Lease的Peon在租约时间内可以直接以本地数据提供Paxos读服务,来分担Leader的只读请求压力。Lease过期的Peon会退回Probing状态,之后通过新一轮的选举产生新的Leader。
Leader会选择当前集群中最大且唯一的Propose Num,简称Pn,每次新Leader会首先将自己的Pn增加,并用来标记自己作为Leader的阶段,作为Ceph Paxos算法中的逻辑时钟(Logical Clock)。同时,每个提案会被指派一个全局唯一且单调递增的version,实现中作为Log的索引位置。Pn及Version会随着Paxos之间的消息通信进行传递,供对方判断消息及发起消息的Leader的新旧。Paxos节点会将当前自己提交的最大提案的version号同Log一起持久化供之后的恢复使用。
常规过程(Normal Case)
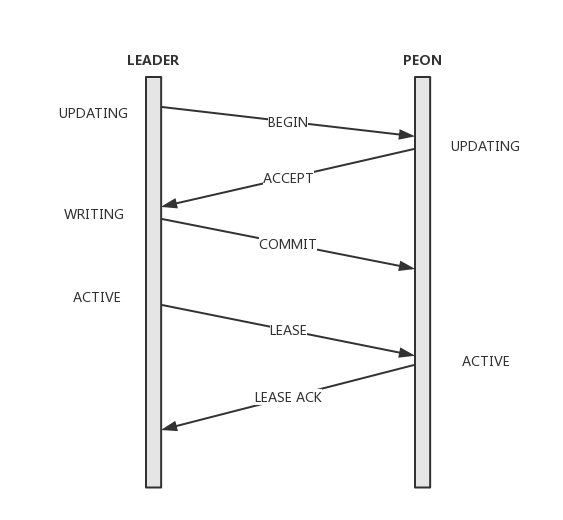
常规服务状态下存在一个唯一的Leader以及一个已经确认的大多数节点Quorum,Leader将每个写请求被封装成一个新的提案发送给Quorum中的每个节点,其过程如下,注意这里的Quorum固定:
- Leader将提案追加在本地Log,并向Quorum中的所有节点发送begin消息,消息中携带提案值、Pn及指向前一条提案version的last_commit;
- Peon收到begin消息,如果accept过更高的pn则忽略,否则提案写入本地Log并返回accept消息。同时Peon会将当前的lease过期掉,在下一次收到lease前不再提供服务;
- Leader收到全部Quorum的accept后进行commit。将Log项在本地DB执行,返回调用方并向所有Quorum节点发送commit消息;
- Peon收到commit消息同样在本地DB执行,完成commit;
- Leader追加lease消息将整个集群带入到active状态。
选主(Leader Election)
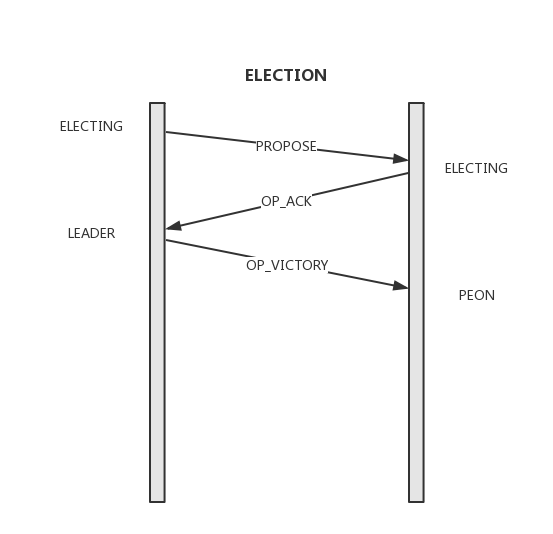
Peon的Lease超时或Leader任何消息超时都会将整个集群带回到Probing状态,整个集群确定新的Members并最终进入Election状态进行选主。每个节点会在本地维护并在通信中交互选主轮次编号election_epoch,election_epoch单调递增,会在开始选主和选主结束时都加一,因此可以根据其奇偶来判断是否在选主轮次,选主过程如下:
- 将election_epoch加1,向Monmap中的所有其他节点发送Propose消息;
- 收到Propose消息的节点进入election状态并仅对更新的election_epoch且Rank值大于自己的消息答复Ack。这里的Rank简单的由ip大小决定。每个节点在每个election_epoch仅做一次Ack,这就保证最终的Leader一定获得了大多数节点的支持;
-
发送Propose的节点统计收到的Ack数,超时时间内收到Monmap中大多数的ack后可进入victory过程,这些发送ack的节点形成Quorum,election_epoch加1,结束Election阶段并向Quorum中所有节点发送Victory消息,并告知自己的epoch及当前Quorum,之后进入Leader状态;
- 收到VICTORY消息的节点完成Election,进入Peon状态;
恢复(Recovery)
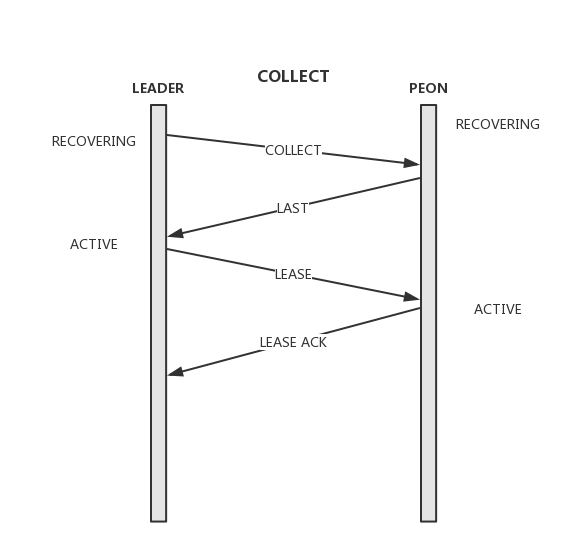
经过了上述的选主阶段,便确定了Leader,Peon角色以及Quorum成员。但由于Election阶段的选主策略,新的Leader并不一定掌握完整的commited数据,因此在真正的开始一致性读写之前,还需要经过Recovery阶段,值得注意的是,Ceph Paxos限制提案的发起按version顺序,前一条提案被commit后才能发起后一条,也就是说Recovery的时候最多只能有一条uncommitted数据,这种做法虽然牺牲了性能,但却很大程度的简化了Recovery阶段及整个一致性算法的实现,而这种性能的牺牲可以由Ceph层的聚合提交而弥补。
- Leader生成新的更大的新的Pn,并通过collect消息发送给所有的Peon;
- Peon收到collect消息,仅当Pn大于自己已经accept的最大Pn时才接受。Peon通过last消息返回自己比Leader多commit的日志信息,以及uncommitted 数据;
- Leader收到last消息,更新自己的commit数据,并将新的commit日志信息通过commit消息发送给所有需要更新的Peon;
- 当接收到所有Peon accept的last消息后,如果发现集群有uncommitted数据,则先对该提案重新进行提交,否则向Peon发送lease消息刷新其Lease;
可以看出,当Leader和Peon之间的距离差距较大时,拉取并重放Log的时间会很长,因此在开始选主之前,Ceph Monitor首先通过如Figure 1所示的Synchronizing来将所有参与Paxos节点的日志信息差距缩小到足够小的区间,这个长度由paxos_max_join_drift进行配置,默认为10。Synchronizing过程中Monitor节点会根据Prob过程中发现的commit位置之间的差异进行数据的请求和接收。
成员变化(Membership Change)
Ceph Paxos的成员信息记录在Monmap中,Monmap可以从配置文件中初始化,也可以在后期加入或删除。Ceph Monitor中引入了Probing阶段来实现Memebership的变化,节点启动、新节点加入、Paxos各个阶段发生超时、发现新的prob消息、Monmap信息发生变化时都会通过boostrap进入到Probing状态,这个状态下Monitor节点相互发送prob消息来探测对方存在来生成并交互Monmap信息。而这个过程中整个Paxos集群是停止对外提供服务的。
日志截断(Log compaction)
通过上面的描述已经知道,Ceph Paxos的Log中记录了每个提案的内容,这些内容本质是对节点状态机的一组原子操作。随着集群的正常提供服务,Log数据会不断的增加,而过多的Log不仅会占用存储资源,同时会增加日志回放的时间。所以Ceph中引入了一套机制来删除旧的Log数据。每次提案commit成功后,Monitor都会检查当前的Log数据量,超过某一配置值后便会进行截断(trim),这个保留的长度由paxos_min进行控制,默认是500。Monitor中用first_commited来标识当前保留的最早的Log的version号,trim过程简单地删除一定量Log并修改first_commited内容,需要数据恢复时,如果需要小于first_committed的内容,则会在如Figure 1所示的Synchronizing过程中进行数据的全同步。
一致性选择
1,State Machine System
Ceph monitor选择了State Machine System而不是Primary Backup System。Log中存储的内容以及Paxos节点之间的交互数据都是像Put,Erase,Compacat这样的幂等操作;而在commit后才会真正写入到状态机。
2,每次只能一条提案
Ceph Paxos的提案发起严格有序,并且只有前一条Log commit后才会发起新的提案,这也就保证集群最多只能有一条uncommitted的提案,这也就简化了Recovery的实现逻辑。能这样做也是由于Ceph Monitor上层的聚合提交等减少对一致性协议执行的机制大大降低了Ceph Paxos对性能的要求。
3,固定的(Designated) Quorum
对Paxos算法来说,无论选主过程还是正常的访问过程,都需要保证有大多数节点(Quorum)的成功,通常这个Quorum每次是不固定的,而Ceph Paxos选择在选主成功后就确定的生成一个Quorum集合,之后的所有操作,都只向这节点发出,并等待集合内所有节点的答复,任何的超时都会重新通过bootstrap过程退回到Probing状态。猜测这里更多的是针对实现复杂度的考虑。
4,双向的Recovery方向
由于Ceph Paxos的选主策略仅根据节点地址的大小选择Leader,就导致成为Leader的节点可能并没有最新的数据,因此在提供服务前Leader需要先在Recovery阶段恢复自己和集群的数据,Recovery的数据方向包括从Peon到Leader和Leader到Peon两个方向。
5,使用Lease优化只读请求
Ceph Paxos引入了Lease机制来支持Peon分担Leader压力,在Lease有效的时间内,Peon可以使用本地数据来处理只读请求;Peon在接收到一个新的提案开始是会先取消本地的Lease,提案commit后或Leader的Lease超时后Leader会刷新所有Peon的Lease;
6,Leader Peon同时检测发起新的Election
Leader和Peon之间的Lease消息同时承担了存活检测的任务,这个检测是双向的,Leader长时间收不到某个Peon的Lease Ack,或者Peon Lease超时后依然没有收到来自Leader的刷新,都会触发新一轮的Election。
代码概述
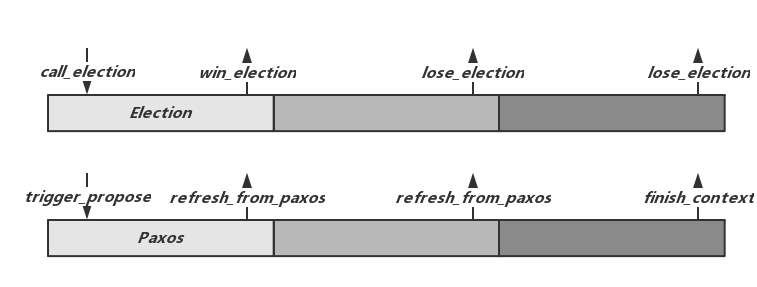
Ceph Monitor中Paxos相关的内容散布在不同的类型中,主要包括Monitor,Election,Paxos几个类:
Monitor中维护了如Figure 1中的节点状态转换,并且在不同阶段调度Election及Paxos中的相关功能。同时Monitor也承担着为其他类提供全局数据的功能。Monitor通过boostrap方法发起Probing生成或修改Monmap,并发现节点之间的数据差异,当差异较大时会调用start_sync进入Synchronizing过程。
Election主要负责选主过程,Monitor会在Probing及Synchronizing过程结束后通过call_election开启选主逻辑。Election选主结束后分别调用Monitor的win_election和lose_election将控制权交还给Monitor。win_election和lose_election中,Monitor完成节点的状态变化,并分别调用Paxos的leader_init和peon_init方法开始Paxos作为Leader或者Peon的逻辑。Paxos由Leader发起Recovery过程,之后进入Active状态准备提供服务。
上层的写操作会通过Paxos的trigger_propose发起。提交成功后,Paxos会调用Monitor的refresh_from_paxos告知上层,同时,上层也可以向Paxos的不同阶段注册回调函数finish_context来完成上层逻辑,如pending_finishers或committing_finishers回调队列。
参考
RADOS: A Scalable, Reliable Storage Service for Petabyte-scale Storage Clusters
choices in consensus algorithm
Vive La Diffe ́rence:Paxos vs. Viewstamped Replication vs. Zab