Why Raft never commits log entries from previous terms directly
熟悉Raft的读者知道,Raft在子问题Safty中,限制不能简单的通过收集大多数(Quorum)的方式提交之前term的entry。论文中也给出详细的例子说明违反这条限制可能会破坏算法的Machine Safety Property,即任何一个log位置只能有一个值被提交到状态机。如下图所示:
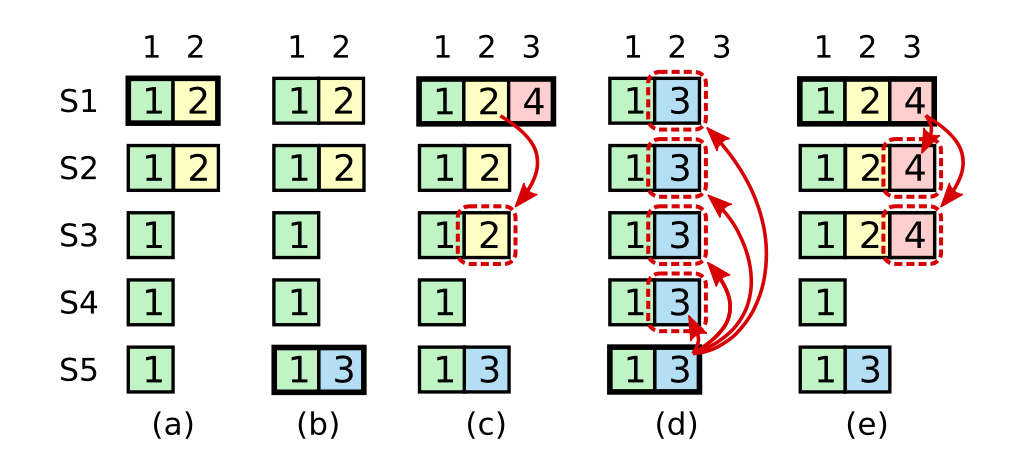
简单的说,c过程中如果S1简单的通过判断大多数节点在index为2的位置的AppendEntry成功来commit值2,那么后续S5成为Leader后,由于自己的值3拥有比2更大的term,导致用值3将已经commit的2覆盖。因此Raft限制只能通过判断大多数的方式提交当前term的entry,进而对之前的entry间接提交,如过程e所示。
Raft never commits log entries from previous terms by counting replicas. Only log entries from the leader’s current term are committed by counting replicas; once an entry from the current term has been committed in this way, then all prior entries are committed indirectly because of the Log Matching Property.
那么导致这种问题的根本原因是什么?以及为什么增加这个限制后就可以解决问题呢?Raft本质上是一种(multi-)Paxos,可以认为是对Paxos加了限制而得到的更简单易懂的一致性算法,因此本文尝试从Paxos出发来回答上面的两个问题。
Paxos
作为一致性协议,Paxos需要作出Liveness和Safty两方面的保证,简单的说:
- Liveness:最终一定有value被chosen
- Safty:只有一个value最终被chosen,且这个value一定是之前被propose过的
为了保证Liveness,Paxos要求每个acceptor必须接受收到的第一个value:
P1. An acceptor must accept the first proposal that it receives.
同时,单个Paxos实例允许不止一个propose最终被chosen,但要求所有被chosen的propose必须有相同的值,从而也保证了Safty。
P2. If a proposal with value v is chosen, then every higher-numbered pro- posal that is chosen has value v.
算法细节上,Paxos要求每个propose需要通过第一阶段的Propose及Promise过程在得到大多数节点对自己propose num认可的同时,也获得可能存在的之前的最大propose num发起的value,并且用自己的更大的propose num对相同的value进行第二阶段的重新提交。这一步非常关键,试想这样一种场景,一个拥有三个acceptor的Paxos集群中,三个acceptor,a1,a3分别在不同的propose num accept不同的value:
a1: (v1, pn=1)
a2:
a3: (v2, pn=2)
此时a3宕掉,新的proposer p3选取新的pn=3,尝试让集群达成一致,由于a3无法响应,p3从a1,a2获得当前最大pn的值为(v1, pn=1),假设p3没有用自己的pn提交并最终Commit,则会出现:
a1: (v1, pn=1)
a2: (v1, pn=1)
a3: (v2, pn=2) down
若此时a3恢复,便可能被新的proposer p4因读取到集群最大pn的值为(v2, pn=2)而将之前p4的提交覆盖,损害一致性。因此Paxos要求p3用自己的pn重新提交v1:
a1: (v1, pn=3)
a2: (v1, pn=3)
a3: (v2, pn=2) down
Paxos to Multi-paxos
Paxos算法分为两个阶段,第一个阶段中节点通过Propose及Promise过程得到大多数节点对自己propose num的认可;之后在第二个阶段中通过Accept请求广播自己的提案值,并且在收到大多数的Ack后进行Commit。那么当我们面对一连串提案而不是一个单独的提案的Multi-Paxos时,很自然的优化就是选择一个Coordinator,由这个Coordinator来发起所有提案的阶段二,从而将Paxos阶段一中的Propose及Promise过程省略。相当于每一次Propose及Promise的结果都是这个Coordinator获胜。
由于所有的value都是由这个Coordinator发起的,是不是就不存在上面说到的不同propose提交同一个值了呢?不是的,只是这种情况被减少到了重新选择Coordinator后的Recovery过程,可以看出每个阶段的Coordinator都相当于上述Paxos的一个Proposer,因而新的Coordinator可能会发现之前的Coordinator发起的值,但其无法判断这个值是不是已经被Commit,因为旧的Coordinator可能是在本地Commit并返回Client之后,通知其他节点Commit之前的空隙宕掉的。因此新的Coordinator安全的做法就是用自己的propose num重新发起并尝试提交这个value。对于切主后需要Reovery的位置需要一个完整的Paxos阶段一、阶段二过程。这个过程中同样要求Coordinator用自己的propose num对已有的value进行重新提交。
Multi-paxos to Raft
可以看出,Raft就是很典型的采取了这种有Coordinator模式的Multi-paxos。Coordinator在Raft中称为Leader,propose num称为term。自然地,Raft中新Leader也会发现旧Leader留下的log entry。因此正确的做法是新Leader用自己的term重新对这个entry进行提交,但由于Log的限制,新Leader没有办法修改这个entry中记录的term,而任由这个entry存在而不修改却将其提交也是不行的,因为entry中过时的term可能会导致未来被其实比当前新Leader小的term的值覆盖,也就是文章开头提到的错误。
Raft的隐含Term
通过上面的追本溯源,我们知道造成这个问题的原因是,log entry中的term无法显式地修改而使得后来的Leader无法得知可能已经被Commit的entry提交时所用的term,从而没有办法以此来作出后续的决策。Raft采用了一种很巧妙的办法来隐含的标定这条entry的term,这就是在log的末尾追加一条记录当前term的log entry,并尝试提交这个entry。Raft选新主时需要比较日志的新旧,最后一个entry的term大小优先于日志长度:
Raft determines which of two logs is more up-to-date by comparing the index and term of the last entries in the logs. If the logs have last entries with different terms, then the log with the later term is more up-to-date. If the logs end with the same term, then whichever log is longer is more up-to-date.
这就相当于给了日志中的所有entry一个隐含的term,这个term等于最后一条entry的term。从而完美的解决了文章开始提到的问题。
回顾总结
- 单个Paxos实例为了保证Safty,要求发现已有值时,需要用自己的propose num重新对这个值进行提交。
- Multi-paxos重新选主后,新的Coordinator需要用自己的propose num对需要Recovery的位置进行重新提交。
- Raft无法重置log entry中的term。
- Raft通过增加新的记录当前term的entry,来隐含地提升之前所有log的term,从而解决了文章开头提出的问题。
参考
Paxos Made Live - An Engineering Perspective
In Search of an Understandable Consensus Algorithm