从Paxos到区块链
本文希望探讨从Paxos到PBFT(Practical Byzantine Fault Tolerance),再到区块链中共识算法Pow的关系和区别,并期望摸索其中一脉相承的思维脉络。
问题
首先需要明白,我们常说的一致性协议或共识算法所针对的问题,简单的说就是要保证:
即使发生网络或节点异常,整个集群依然能够像单机一样提供一致的服务,即在每次成功操作时都可以看到其之前的所有成功操作按顺序完成。
故障模型
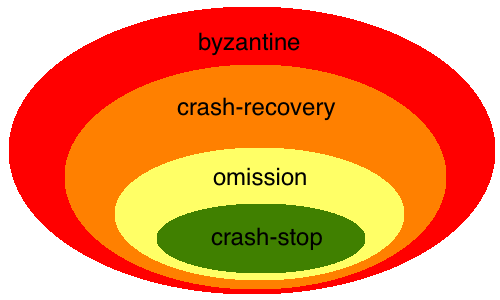
正式开始之前,还需要了解分布式系统中几个常见的故障模型,这也是这几个不同算法存在的本质原因。按照最理想到最现实的顺序大体有以下几种:
- Crash-stop Failures:故名思议,一旦发生故障,节点就停止提供服务,并且不会恢复。这种故障模型中的节点都按照正确的逻辑运行,可能宕机,可能网络中断,可能延迟增加,但结果总是正确的;
- Crash-recovery Failures:相对于crash-stop failures,这种故障模型允许节点在故障发生后恢复,恢复时可能需要一些持久化的数据恢复状态(Omission Failures);
- Byzantine Failures:这种故障模型需要处理拜占庭问题,因此也是最难应对的,相对于上面的两种故障模型,不仅仅节点宕机或网络故障会发生,节点还有可能返回随机或恶意的结果,甚至有可能影响其他节点的正常运行。
如下图(图来源)所示,三种错误模型的限制逐渐放宽,逐步复杂:
本文涉及的三种算法便是基于不同故障模型的产物:
- Paxos基于Crash-recovery Failures,因此适用于安全的网络环境,被在内网服务的存储或协调服务大量使用;
- PBFT和区块链则是基于Byzantine Failures,面向更复杂的网络环境。
Paxos
从上面的讨论已经知道,Paxos面临的是一个可能失败但绝不会出错的相对安全的网络环境,因此可以无条件的信任所有节点的交互结果。针对单个提案有如下阶段:
- Prepare:Proposer选取proposal number n并向所有acceptor发送Prepare消息;
- Promise:Acceptor收到Prepare消息后,如果n不小于其Promise过的任何其他Prepare消息,则答复Promise,保证不再响应小于n的Accept消息,并返回当前proposal number最大的proposal内容;
- Accept:Proposer收到过半数对Prepare消息的答复后,用proposal n及收到的最大number最大proposal内容,向所有acceptor发起Accept请求;
- Ack:Acceptor在不违背自己做出的承诺的情况下Accept,并返回Ack;
- Commit:Proposer收到大多数节点的Ack,完成并广播Commit消息通知集群。
这里保证算法正确无误,为一致性保驾护航的根本是其中一个不起眼的点:大多数(Majority),这也是包括Paxos在内的所有一致性算法证明正确性的关键所在:
- Propose发起Accept前,确保得到了大多数节点的Promise,就保证不会有两个不同的提案内容同时被不同节点Accept。
- 由于每个提交的提案都收到了大多数节点的Ack,即存在于大多数节点上,那么只要有大多数节点可以正常服务时,就一定可以在Promise过程中拿到已经Accept的提案内容,从而阻止后续改变提案内容。
这里的大多数为超过半数节点。
PBFT
如果将Paxos面对的故障模型放宽到Byzantine Failures,即可能存在一定量的恶意节点:
- 可能做出随机的或错误的答复或请求;
- 可能延迟或拒绝应答;
- 可能通过拒绝服务攻击正常节点,使之不能正常提供服务;
- 但不能破坏当前的加密技术。
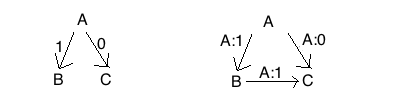
就是PBFT(Practical Byzantine Fault Tolerance)算法所面临的环境了,先通过一个图(图来源)直观的了解PBFT实现的思路:既然恶意节点可能撒谎,就通过加密签名以及节点之间的相互转发来发现,如下右图。
PBFT的算法过程如下图,假设最多有f个恶意节点:
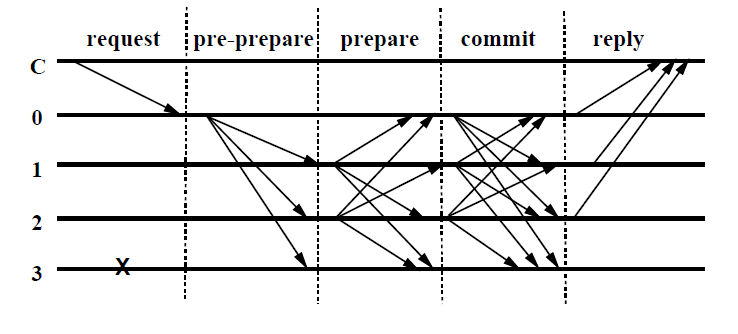
- Cient 向Primary发送Request
- Primary向所有节点发送Pre-prepare消息,包括view号、sequence以及Requst消息;
- Acceptor验证消息,如果v是accept过最大的,则进入Accept状态,并将这个Request联通对应的Primary的签名及自己签名以Prepare消息在集群中广播;
- 当某个节点集齐一个Pre-prepare加2f个Prepare消息时,进入Commit,并发送Commit,并广播Commit消息
- 再收到2f+1个Commit消息后,执行并向用户返回。
- 用户收到至少f+1个相同内容的答复时便成功。
同样PBFT也依赖大多数来保证算法正确,假设有f个节点在超时时间内没有返回,我们并不能确定他们全都是恶意节点,也有可能是被拒绝服务攻击而无法响应的正常节点;也就是说剩下的响应节点中仍然有可能包括全部f个恶意节点,为了摒除他们的影响,正确的答复就至少达到f+1个。
这里的大多数为至少有2/3节点正常响应,并在其中达到过半数。
区块链共识算法
PBFT虽然已经解决了拜占庭问题,但有两个明显的缺陷:
- 大量的网络交互:每个阶段的大量广播消息;
- 对大多数的判断是跟节点总结数相关的,因此集群成员需要稳定,很难变化。
这两个问题导致其不能更广泛的应用在常规的互联网环境中。这就需要一种新的对大多数的定义和判断。区块链中提出了一种即聪明又昂贵的思路:工作量证明(Proof-of-Work)。
先来看区块链的基本思路:
- 为了能在无中心的环境中避免重复支出(double-spend)问题,就需要将所有的交易广播到整个网络,并且整个集群需要对交易历史达成一致;
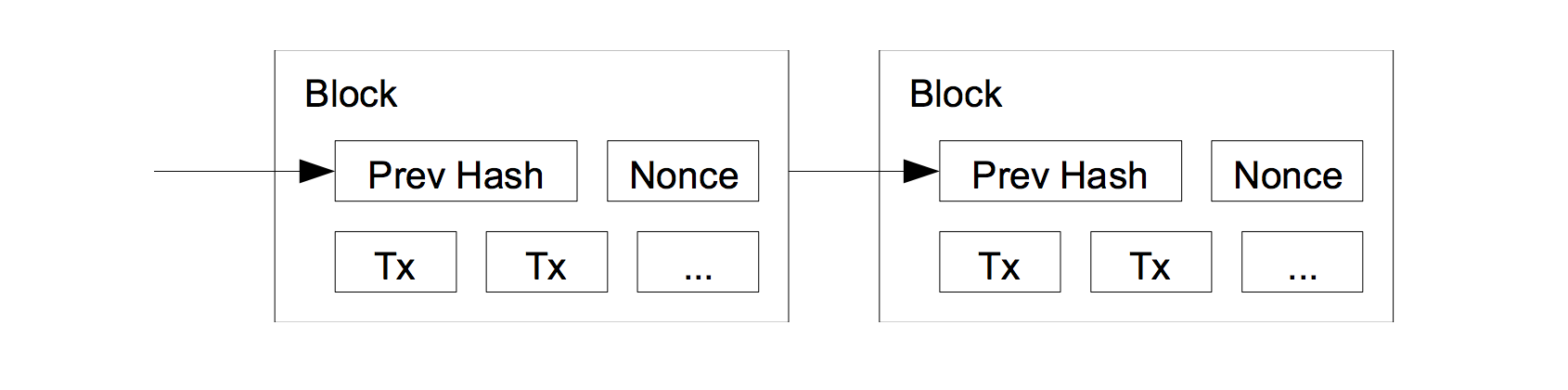
- 因此引入了区块Block,每个Block中包含多个当前网络中的交易事务;
- 每个区块会对当前区块事务以及前一个区块计算一个哈希值,从而将Block串成一个链表。这个哈希值也证明某一时刻某个事务的存在;
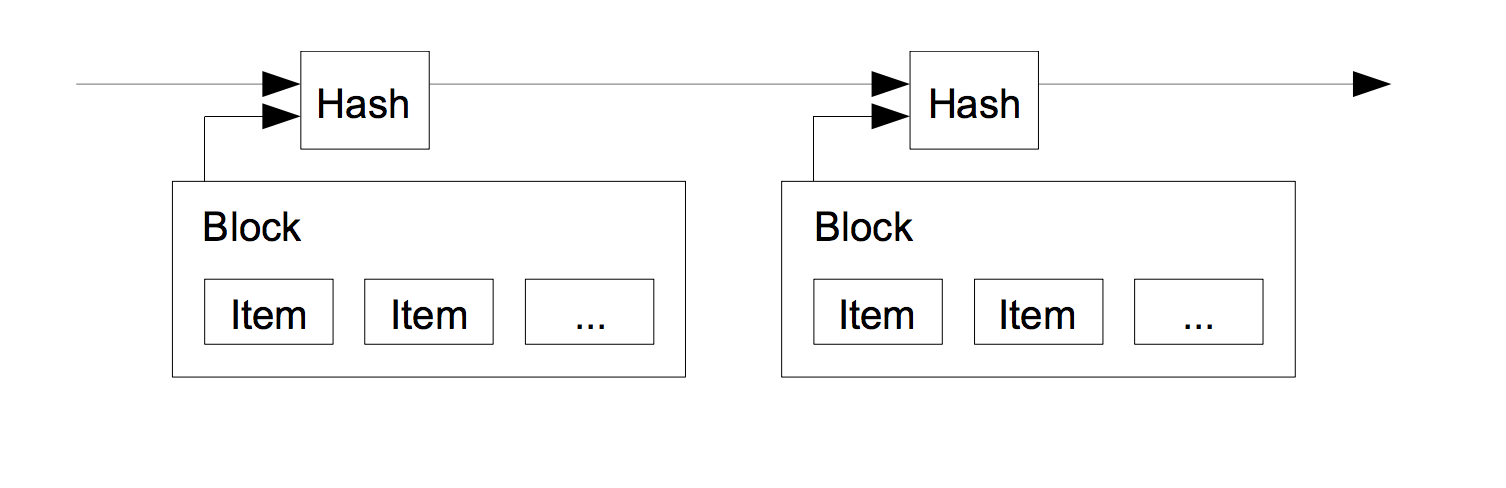
现在问题变成了:如何让集群中的大多数对同一个Block链达成一致。在这样一个节点可以随时加入或退出的开放的网络环境中,基于节点数量的大多数判断不再适用。工作量证明(Proof-of-Work)用计算能力来确定大多数:
-
极大增加生成Block需要的计算量:要求Block在计算哈希值时,通过选择参与哈希值计算的Nonce,来获得一个前缀有指定个0的哈希值:hash(Pre-Block + Nonce + All Transaction) < X;
- 由于Block链的生成方式,篡改任何一个Block都需要对其后所有Block的哈希值重新计算;
- 当一个Block后有足够数量个后继Block时,认为攻击者不足以获得足够颠覆整个链的计算能力时,就算对当前最长的主链达成了大多数,从而完成记账;
- 给予消耗计算能力创建Block的矿工一定奖励,从而:
- 加快主链的生成速度,增加恶意节点难度,减少记账时间;
- 对于拥有足够大量计算能力的节点,诚实的参与到主链的创建中比篡改Block能获得更大的收益,这就是属于博弈论的内容了。
这里的大多数是指维持一定数量Block的主链领先的计算能力。
总结
无论Paxos,PBFT还是Pow,都是要解决不同网络环境下的一致性问题,而一致性问题的重点在大多数,无论正常的处理流程还是故障恢复流程,都依赖两个不同的大多数一定有交集的特性。
- 内网安全环境下的Paxos,超过半数节点即可确定大多数;
- 考虑拜占庭容错的PBFT,由于需要面对的恶意节点不仅可能作出错误答复或不答复,还有可能阻止正常节点响应,因此需要在至少2/3个能响应的节点中达到过半数。
- 工作量证明(Pow)用维持一定数量Block的主链领先的计算能力作为大多数,从而满足任意节点可能随时加入退出的更为广泛的环境需求。
虽然区块链有着明显的局限和场景缺失,前途扑朔迷离,但这里还是要感慨下。凯文凯利在《失控》中曾写到:
This is a universal law of vivisystems: higher-level complexities cannot be inferred by lower-level existences.
是说群体会表现出其组成个体无法理解的复杂性,而人类作为一个群体, 一直以来最伟大的两个群体表现,互联网和金融体系,在群体最本质的特征分布式上深度融合,无论未来如何,未来已来。
That out of three sounds he frame, not a fourth sound, but a star.
—-Browning
参考
Practical Byzantine Fault Tolerance
Bitcoin: A Peer-to-Peer Electronic Cash System
Why Raft never commits log entries from previous terms directly